2022. 8. 29. 01:38ㆍML, DL/CS182
CS 182: Deep Learning
Head uGSI Brandon Trabucco btrabucco@berkeley.edu Office Hours: Th 10:00am-12:00pm Discussion(s): Fr 1:00pm-2:00pm
cs182sp21.github.io
이번 강의에선 대표적 생성 모델 중 하나인 Generative Adversarial Networks, GANs에 대해 배운다.


Latent model에서는 z를 p(z) (보통 N(0, I)와 같은 simple distribution)에서 sampling, p(x | z)에서 x를 sampling해서 이미지를 생성했다. Encoder로 random number vector를 생성 후 그걸 이미지로 바꾼 것인데, 그냥 모델을 통으로 훈련해서 한 번에 이미지를 만드는 건 어떨까? 두 distribution이 서로가 서로에게서 생겨났다고 할 수 없게, similar하다고 population level에서 생성하는 것이다. 아래 사진은 둘 모두 generation image인데, 이렇게 구별하기 힘든 경우 population level에서 매우 좋은 분포라고 한다.


이제 discriminator는 어떤 이미지가 real인지, fake인지 알려주는 classification network가 된다. 당연히 real image는 dataset에서, fake image는 generation을 통해 얻을 수 있다. 이때 discriminator가 출력하는 확률이 곧 generator에 대한 loss로 작용할 수 있다. 결과 이미지가 얼마나 현실적인지에 대한 정도를 나타내는 것과 같으니 이걸 generator의 negative loss로 사용해서 더욱 realistic한 이미지를 생성하도록 하는 것이다.
자 그러면 generator가 생성한 이미지는 discriminator에 들어가 분류된다. realistic한 이미지를 뽑고 싶은 generator는 discriminator가 자신이 생성한 이미지를 더욱 real하다고 생각하게 해야만 한다. 반대로 discriminator는 그조차도 완벽하게 검출하고 싶어할 것이다. 때문에, 이 둘은 서로 경쟁 관계에 놓이게 된다.

최종 목표는 이미지 생성이기에 generator가 이기도록 해야 한다.
먼저 dataset에서 true image를 뽑고, generator에서 fake image를 sampling한다. 이때 prior로 z를 sampling하고 그 z로 다시 samping한다. Phi가 parameter인 discriminator를 true dataset, false dataset을 사용해 update한 뒤, -log D(x)를 G의 loss로 사용해 update한다.
D, G는 한 step만큼만 업데이트한다. 이를 iterative하게 반복한다. G의 경우 deterministic mapping을 사용할 수도 있고, 다른 것을 써도 된다. G의 loss로 -log D(x) 대신 다른 것을 써도 된다고 한다.
이런 모델을 가리켜 Generative Adversarial Network (GAN) 이라고 한다.

G(z)는 생성한 이미지 x가 진짜인지 아닌지 구별할 수 없는 상황을 원한다. 그러기 위해선 discriminator가 0.5의 값을 내서 진짜인지 가짜인지 구별할 수 없도록 해야 한다(실제 이미지보다 더 realistic해질 수는 없으므로). 이를 위해서는, 그냥 realistic image를 생성하는 게 아니라 가능한 "모든" realistic image를 생성해야 한다. 왜일까?

개와 고양이 사진이 정확히 반씩 있다고 생각해보자. 우리의 generator는 개에 대해서 굉장히 좋은 성능을 자랑해 realistic한 이미지를 만들 수 있다. 하지만 고양이를 너무도 싫어한 generator는 제대로 된 고양이 사진을 생성하지 못한다. True dataset과 False dataset은 정확히 같은 숫자이고, False dataset에는 개 사진만 있다고 하자.
이때 discriminator는 false image가 없는 고양이 사진에 대해선 무조건 1(true)의 값을 낼 것이고, 개 사진의 경우 전체 사진 중 25%만 true이니 0.25의 확률로 true라고 생각할 것이다. 따라서 generator는 굉장히 realistic한 개 사진을 생성함에도 불구하고 discriminator를 속일 수 없다. 그렇기에 가능한 모든 realistic image를 만들 줄 알아야 게임에서 이길 수 있고, 즉 GAN은 entire distribution을 얻는 방향으로 학습하게 된다.실제로 사용 시 GAN은 mode collapse problem을 겪기도 한다. 이는 일종의 overfitting으로, entire distribution을 찾는 데 실패하는 걸 뜻한다. 바로 위의 예시를 들면 개의 distribution만 찾은 경우 이 문제가 발생한 것이다. 이 경우 optimize가 어렵다.

Small GANs으로 작은 이미지들은 잘 만들어냈지만, 이미지가 커지니 알아보기 힘들어진다.

High-res GANs는 높은 해상도의 이미지도 잘 생성한다. 하지만 일부 방 사진에는 살짝 부자연스러운 부분이 보인다.

위의 2개와 다르게 Big GANs는 여러 class에 대해 generation을 할 수 있는 모델이다. 좋은 성능을 가지나, 오른쪽 밑의 테니스볼 강아지같은 뒤틀린 것이 나올 수 있다고 한다.

Conditional하게 이미지를 생성할 수도 있다. 위 예시들을 보면 주어진 이미지에 기반해 다른 것들을(사진->지도, 낮->밤 등) 생성해낸 모습이다.

기본적인 2-player GAN의 경우 V(D, G)를 G에 대해 minimize하는 동시에 D에 대해 maximize한다.
D(x)는 discriminator가 판단한 true image x가 True일 확률, D(G(z))는 generated image G(z)가 True일 확률이다. 이때 true / false의 binary classification이므로 G(z)가 false일 확률은 1 - D(G(z))이니 이것을 사용한다.
즉 V(D, G)의 첫 번째 term은 x가 진짜일 log probability의 expectation, 두 번째 term은 G(z)가 가짜일 log probability의 expectation이다. G는 각각 0.5, 0.5이기를 원하니 이때 log 값이 최소화되므로 최소화를 원하고, D는 1.0, 0.0이기를 원하니 이때 log 값이 최대화(0)되므로 최대화를 원하는 것이다. V(D, G)는 뭔가 entropy의 음수 꼴 느낌도 나는데, entropy는 uniform distribution일 때 최대이고, 베르누이 분포가 uniform할 경우 두 확률이 0.5, 0.5이니 이때 entropy의 음은 최소가 되는 방식으로도 이해할 수 있는 듯 하다.
이는 nash equilibrium과도 관계가 있는 것 같은데, 잘 이해하지는 못했다.

이제 θ (G의 parameter), Ф (D의 parameter)에 대해 min, max를 구해야 하니 미분을 해야 한다. Ф 는 최대화이니 gradient ascent, θ 는 최소화이니 gradient descent를 해야 한다.
Stochastic gradient descent / ascent를 가능하게 해 gradient를 계산하기 위해 첫 expectation term은 x의 minibatch를 이용하고, 두 번째 term은 같은 수만큼 z를 sampling해서 이용한다. 또한 첫 번째는 negative, 두 번째는 그냥 cross entropy loss로도 볼 수 있다.
Backpropagation 시에 discriminator를 먼저 들어간 후 generator로 간다. 구현 시엔 autodiff software를 사용해 gradient를 계산하면 된다.

재미있게도 V(D, G)를 보면, 어떤 것이 GAN을 optimize해 주는 지 알기 어렵다. 보통 optimum에 convergence 시, 특정한 값이 최소가 되는 걸 생각하면 여기에도 무언가 숨어있을 것 같다는 생각이 든다. 한번 convergence 시 G(z)가 어떤 모습을 띄는 지, D(x)를 G(z)의 function으로 나타내서 알아보자. Outer min에 inner max 형태를 가지고 있으니, inner max인 D는 어쩌면 G의 형태로 식을 나타낼 수 있을지도 모른다.
우측 파란 박스를 보면 p(x)는 positive, q(x)는 negative label로 설정 후 D*를 구해 보자. 기본 loss 식을 D에 관해 미분 후 0이 되는 지점을 찾으면 나오는 D가 바로 D*가 된다 (bayes optimal classifier라고 한다). 같은 방식으로 여기선 negative label distribution이 p_G(x)이므로 (z ~ p(z), x = G(z)로 얻음), G가 fixed되면 convergence 지점에서 optimize가 가능해진다. 이를 써서 식을 다시 정리하면 된다.

그리고 새로운 q(x)를 두 p의 평균으로 정의한다면, V(D*_G, G)를 조금 더 깔끔하게 정리할 수 있다. 뒤의 log 4는 상수이므로 무시하자. 두 KL divergence의 합으로 정리된다. 또는, Jensen-Shannon divergence를 사용해 정리할 수 있다. 두 distribution 간의 measure의 일종인데, 두 개가 같다면 0이 되고, KL-divergence와 다르게 symmetric한 distance measure이다. Convergence 시 당연히 두 distribution이 match에 근접한 상태가 될 것이니 이 항은 최소가 된다! GAN은 두 distribution을 같게 만드는 식으로 학습되는 것이였다.

실제 사용 시 그냥 음의 log probability를 쓰는 것이 조금 더 좋다고 한다. 이는 derivative의 형태에서 기인한다.아래 그래프를 보면 알 수 있지만 기존의 것은 generator가 나쁠 때 gradient가 작아 step 진행이 느리고 좋을 떄 gradient가 크지만, 두 번째 것은 generator가 나쁠 때 gradient가 크고 좋을 때 작아 진행이 더 빠르고 최적점을 찾기 좋은 형태이기 때문.
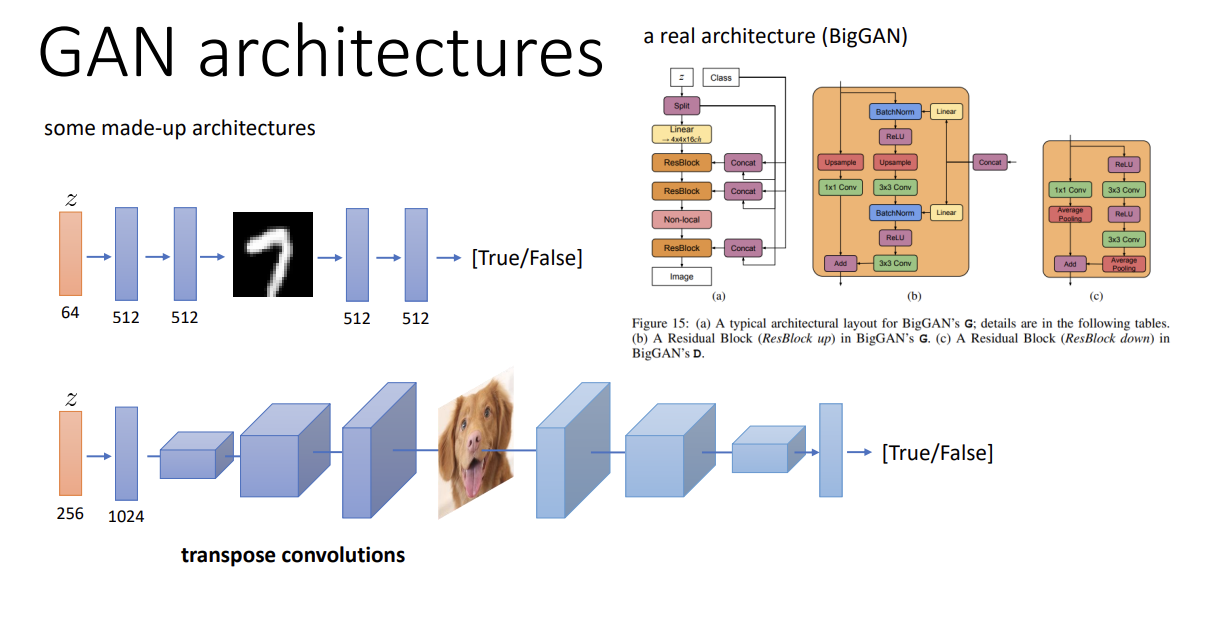
GAN의 discriminator, generator는 그냥 FC layer를 사용할 수도 있고, VAE와 비슷하게 generator는 transpose convolution, discriminator는 convolution을 사용할 수도 있다. BigGAN의 경우가 이를 사용한 것인데, 자세한 내용은 z를 쪼개고... residual block으로 하나씩 넣어주고... 하는 등 복잡하지만 기본 원리는 transpose convolution -> convolution을 사용해 만든 것이다.

특정 class의 image를 생성하길 원할 시, class vector y를 generator, discriminator의 input에 concatenate해 준다.

아무 이미지나 만드는 게 아니라, 한 domain에서 다른 것으로 translate하는 GAN이 CycleGAN이다. 오른쪽의 말을 그대로 얼룩말 사진으로 바꿔버리는 것이 그 예시이다.
문제는 이와 비슷한 language translation problem에선 (English, French)로 data pair가 주어졌지만 여긴 그냥 각자의 사진이 덩그러니 놓여 있다는 것이다. CycleGAN은 두 class 사이의 correspondence를 자동으로 찾아 이를 해결한다.
2개의 conditional generator : G는 X --> Y / F는 Y --> X 와
2개의 discriminator : D_x: generated x가 realistic한가? / D_y: generated y가 realistic한가? 로 이루어진다.
D_x는 real X's image를 positive로, generated X를 negative로
D_y는 real Y's image를 positive로, generated Y를 negative로 판단하는 것이 목표이다.
이때 discriminator들은 주어진 horse와 정확히 같은데 zebra로 바뀐 것을 만들어야지, 임의의 zebra를 생성하면 안 된다 (오른쪽의 예시 사진처럼). 이를 해결하기 위해 cycle-consistency loss를 사용한다.
간략히 설명하면 X -> Y로 바꾼 후 그 Y를 다시 X로 바꿀 경우, 바뀐 것은 원래 X와 같도록 하는 것이다.즉 생성된 Y는 D_y를 속이고, 동시에 거기서 다시 생성된 X는 원래 X와 유사해야 한다. 반대의 경우(Y -> X -> Y)도 마찬가지이다. (아마 이땐 원래 사용하던 V와 이걸 같이 사용하는 것 같다)

요약하자면 GAN은 마치 서로가 경쟁하는 게임과 같고, optimal discriminator를 구해 nash equilibrium에서 minimized되는 object인 Jensen-Shannon divergence를 찾았다. 단 이것이 우리가 실제 nash equilibrium을 찾을 수 있다는 것은 아니다. FC layer 또는 convolutional하게 GAN을 만들고 훈련할 수 있고, cycleGAN을 통해 한 이미지를 다른 특성을 입혀 translation하는 것도 가능하다.
'ML, DL > CS182' 카테고리의 다른 글
| [CS182] Lecture 18 - VAEs, invertible models (0) | 2022.08.27 |
|---|---|
| [CS182] Lecture 17 - Generative modeling (0) | 2022.08.25 |
| [CS182] Lecture 13 - Applications : NLP (0) | 2022.08.19 |
| [CS182] Lecture 12- Transformers (0) | 2022.08.14 |
| [CS182] Lecture 11 - Sequence to Sequence Models (0) | 2022.08.13 |