2022. 8. 13. 23:47ㆍML, DL/CS182
CS 182: Deep Learning
Head uGSI Brandon Trabucco btrabucco@berkeley.edu Office Hours: Th 10:00am-12:00pm Discussion(s): Fr 1:00pm-2:00pm
cs182sp21.github.io
이번 강의에선, 지난 강의에서 배웠던 RNN을 바탕으로 한 Seq-to-Seq model에 관해 배운다.

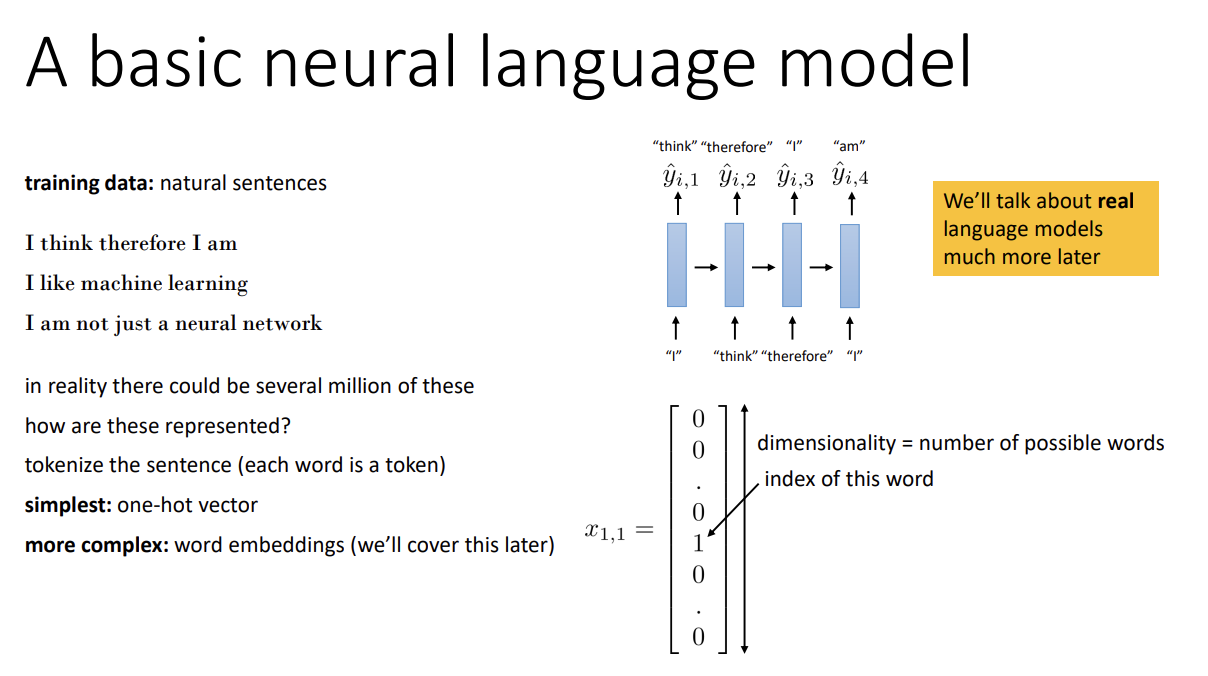
먼저 Language model에 대해 알아보자. Text를 나타내는 sequence에 probability를 주는 model을 language model이라고 한다. 또한 이를 이용해 text를 생성할 수도 있다.
이 경우, sentence를 표현하는 방법은 크게 2가지가 있다.
첫 번째는 단순히 one-hot vector를 사용하는 것이고 (vector dimension은 가능한 모든 word의 수가 될 것이다)
두 번째는 word embedding이라는 방법을 사용하는 것이다.
Word embedding은 continuous-valued vector이고 단어들 간의 semantic similarity를 반영한 representation인데, 이후 강의에서 자세히 다룬다고 한다.
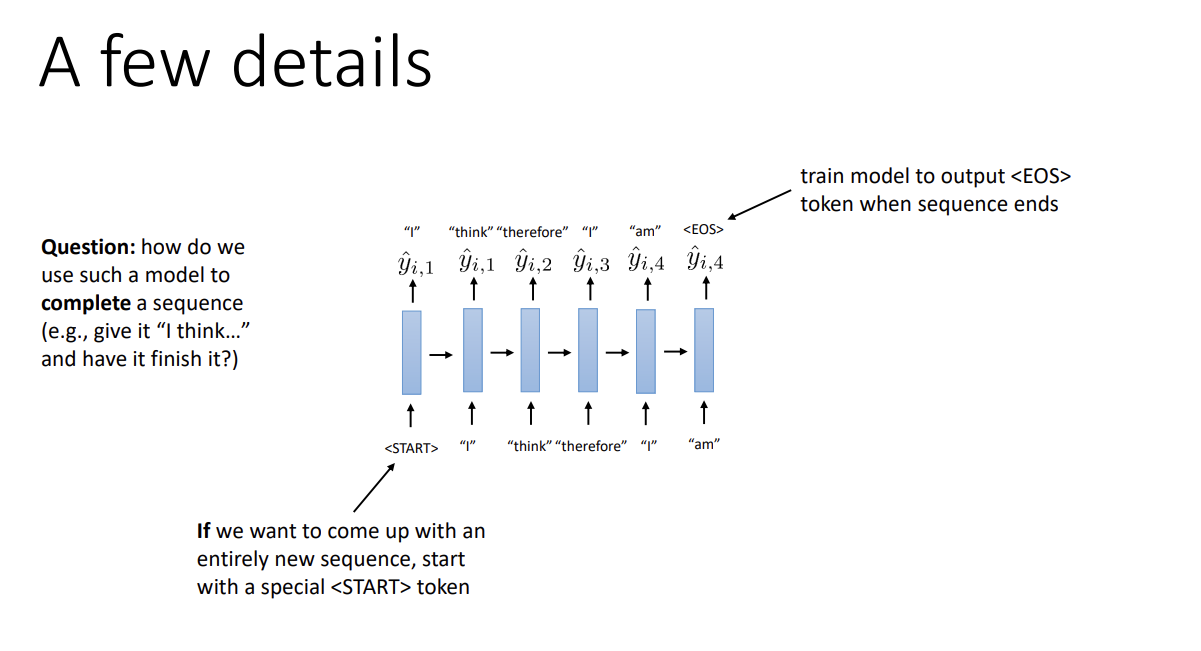
Q) 만약 입력 데이터로 문장의 중간까지만 주고, 유효한 문장으로 끝맺도록 모델을 훈련하고 싶다면 어떻게 해야 할까?A) Token을 받아 생기는 output을 다시 모델에 주는 것이 아닌, 입력받은 끊어진 문장의 token을 입력해서 모델이 해당 문장에 대한 output을 이후부터 출력하게 하면 된다.
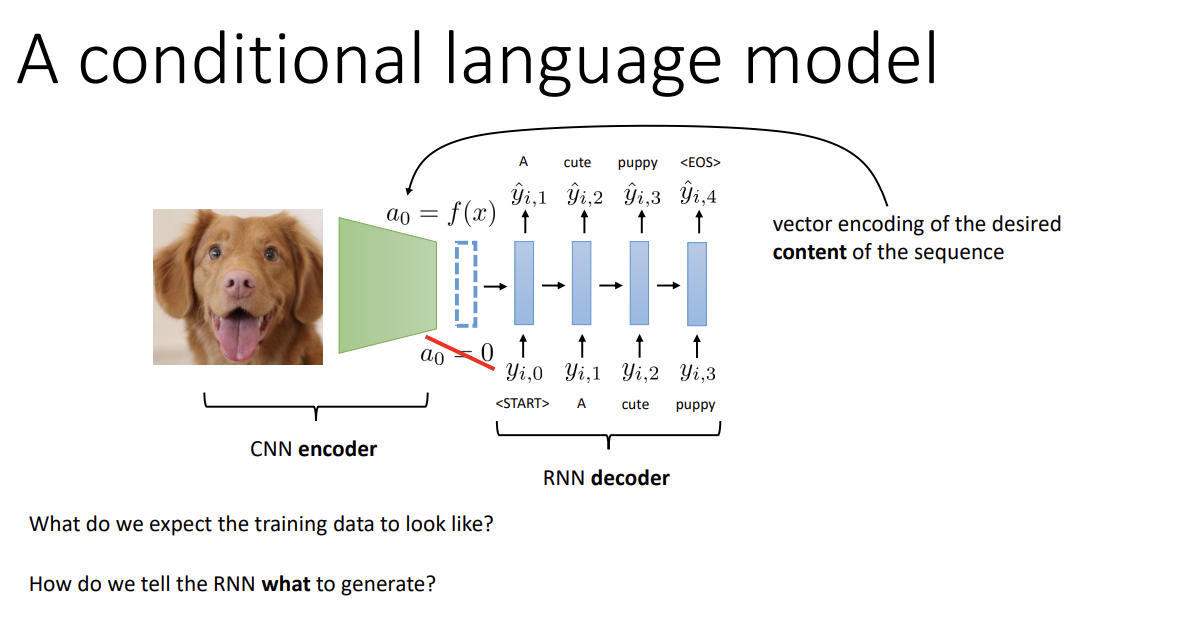
Conditional language model은 특정 input에 대한 text를 생성하는 모델이다. 예를 들어 위의 이미지를 보면,
input으로 이미지를 받아 CNN 구조의 encoder에 넣어 representation을 생성한 뒤, 그것을 RNN decoder의 input으로 사용해 output을 뽑아낸다. 중간의 representation은 저 사진에 대한 정보를 담아야 한다.
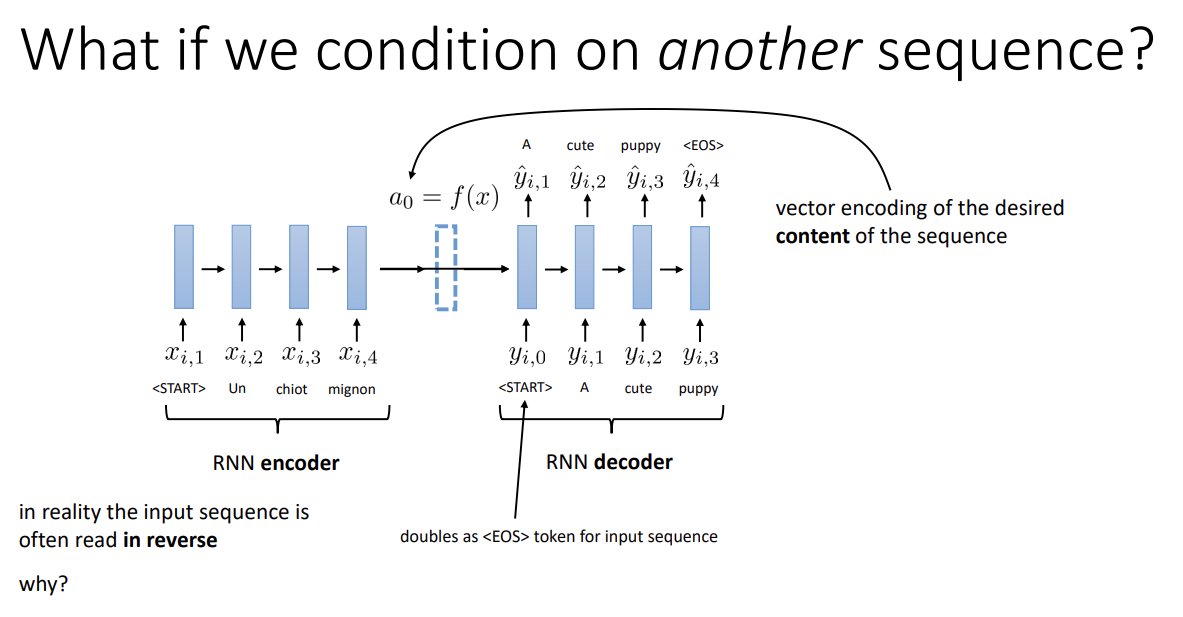
전체 input으로 단지 사진뿐만이 아닌 text도 가능하다. 여기선 encoder도 RNN 구조인 모습을 볼 수 있다.
그 경우 번역 모델이 될 수도 있을 것이고, 텍스트 요약 모델이 될 수도 있을 것이다.
번역 모델의 경우 종종 input sequence를 뒤집는 경우가 있는데, 문장의 시작 부분과 시작 부분이 가까운 편이 직관적으로 더 좋아서 그런 게 아닐까 싶다.
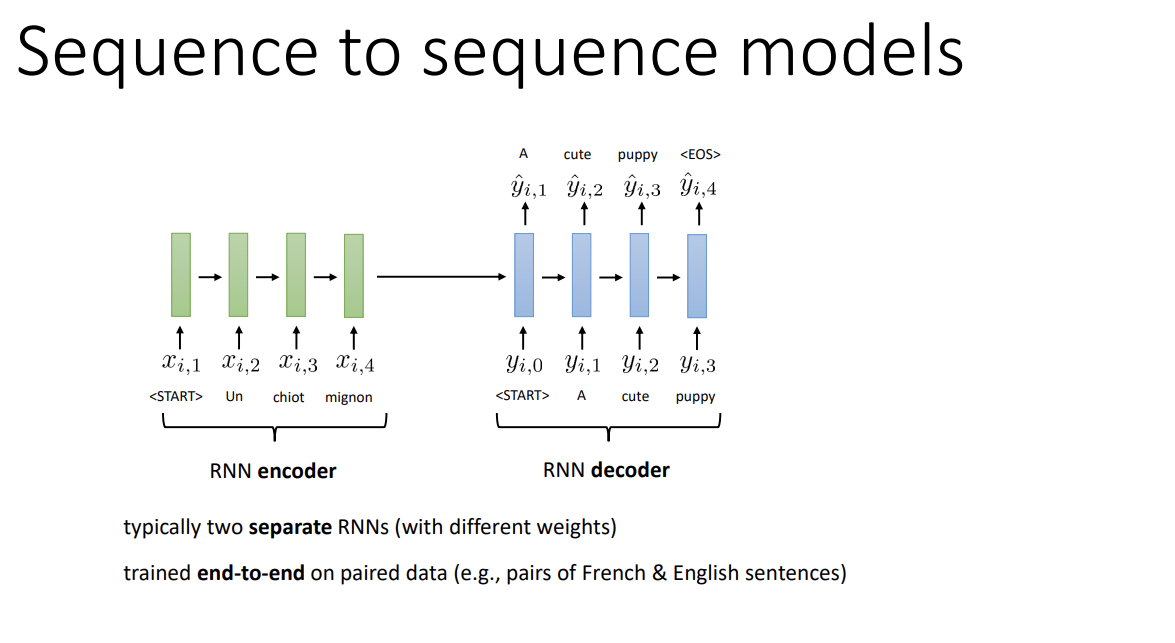
보통은 2개의 분리된 RNN을 사용하나, 이 모델을 하나의 큰 RNN으로도 생각할 수 있다. 만약 그렇다면 input sequence의 <EOS> token은 new sequence의 <START> token과 같아질 것이다.
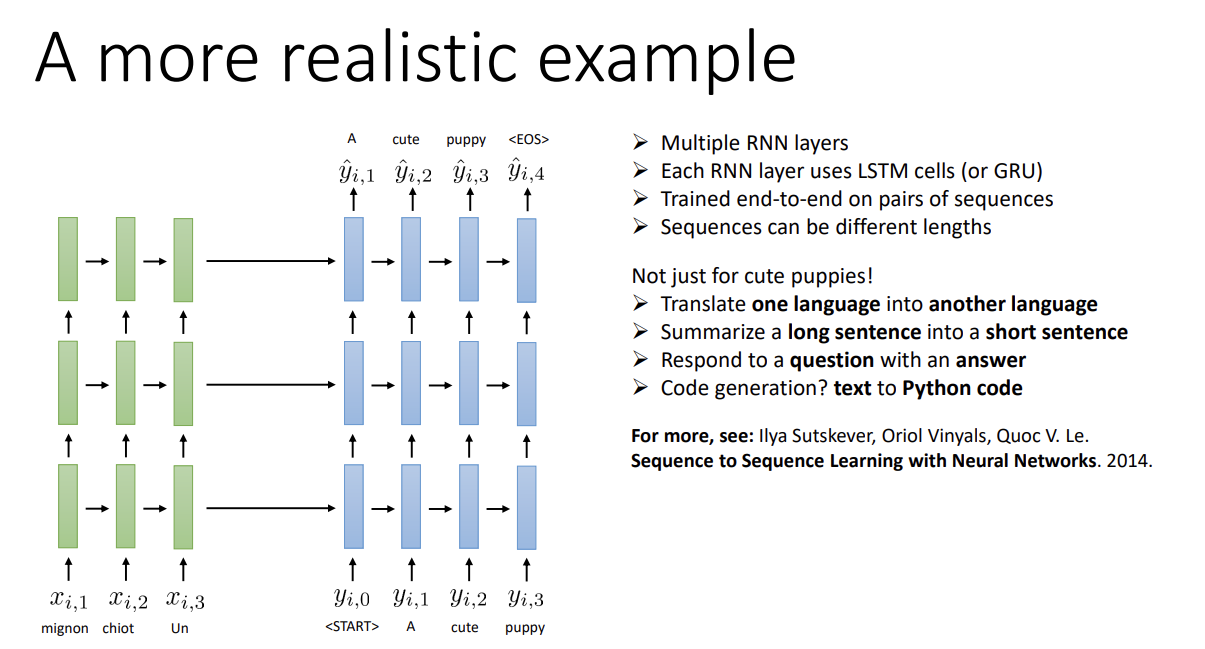
실제로 이를 사용할 때는 RNN layer를 여러 번 쌓은 걸 사용하기도 한다.
각 layer는 LSTM이나 GRU cell을 사용한다.
End-to-end training이고 각 sequence의 길이는 다를 수 있다고 한다.
번역, 문장 요약, 질의응답, 심지어 프로그래밍 코드 생성도 가능하다.
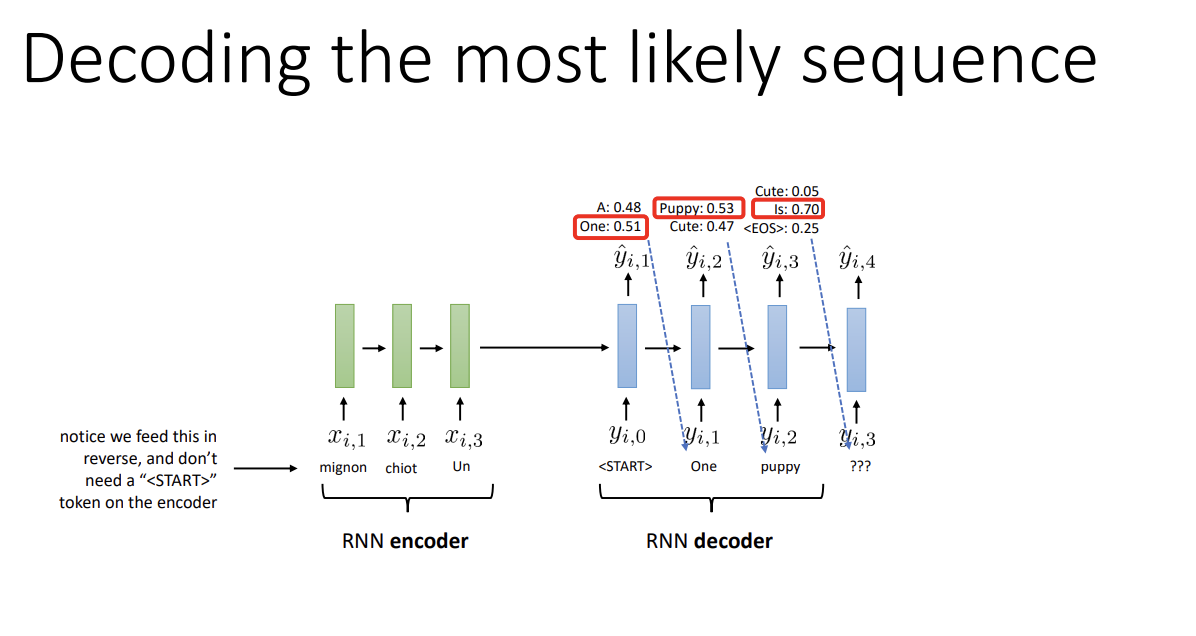
Encoder를 거쳐 나온 sequence는 decoder의 input이 되어 전체 output을 생성한다.
그런데 decoder step에서 정확히 무엇을 해야 할까? 각 layer에서 가장 높은 probability를 가지는 token을 선택하는 것이 가장 먼저 떠오를 것이다.
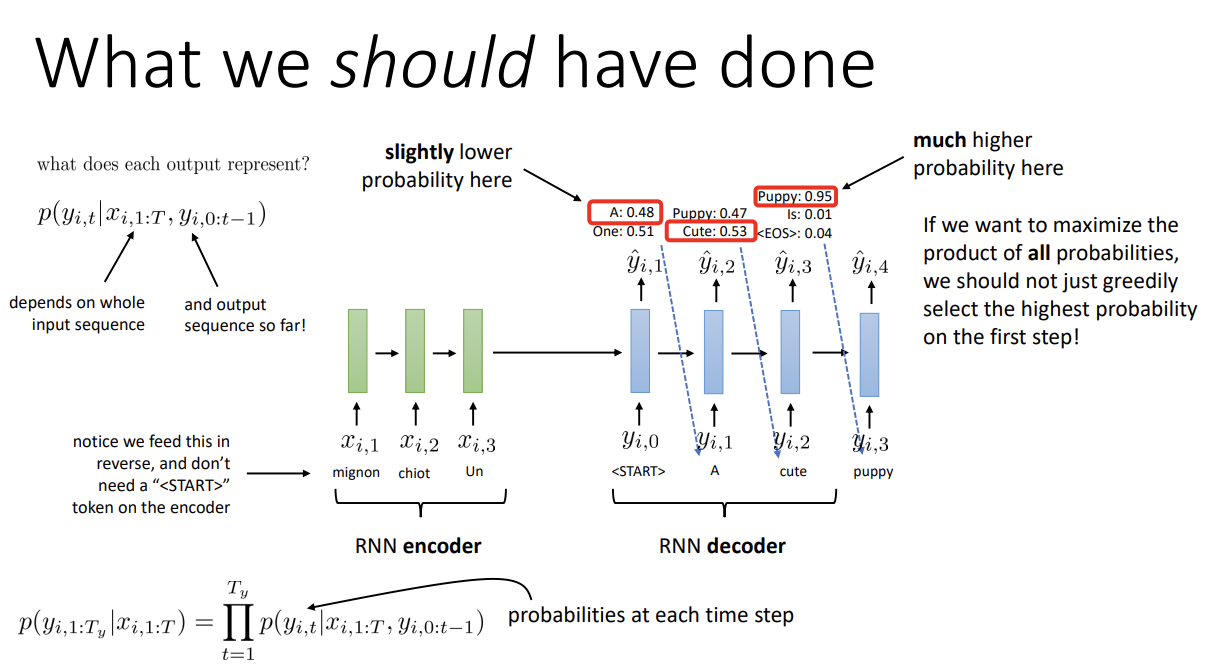
그러나 처음 확률이 조금 낮은 token일지라고, 나중에 token을 뽑을 때 확률이 높아지는 경우가 있다.
따라서, 우리는 전체 확률의 곱을 최대화하는 것을 목표로 해야 하고 greedy한 방식을 사용할 수는 없다.
(왜 확률의 곱인가 하면, 모든 단어 token의 output distribution은 input에 dependent하고
RNN에서 특정 timestep의 단어는 이미 network에 들어간 모든 단어에 dependent하기 때문이다.
때문에 최종 output의 확률은, 이전 모든 단어의 conditional probability의 곱이 된다)
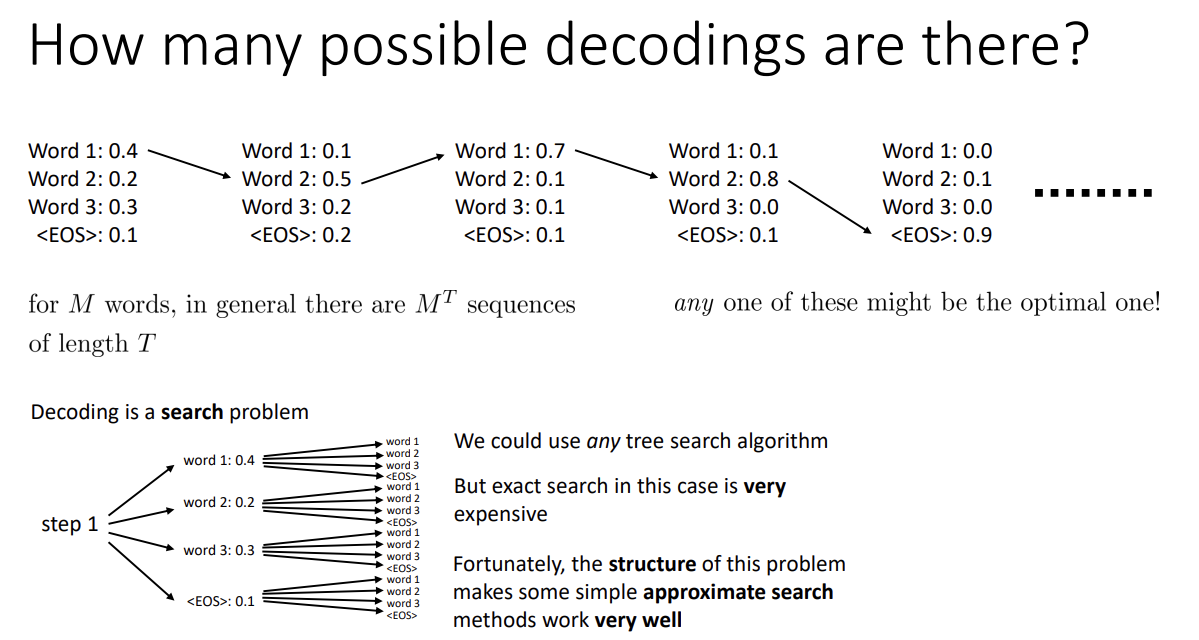
그러면 단어들에 대해 가능한 모든 조합을 생각해야 하는데, 이는 exponential한 개수이므로 모든 조합을 탐색할 수는 없다.

그러나 가장 높은 확률의 단어 선택이 최선은 아니겠지만 그래도 확률이 낮지는 않다는 추측이 가능하고,
이를 위해 Beam search라는 알고리즘을 사용한다.
탐색을 하며 k개의 가장 좋은 sequence를 저장하고, 매 step마다 이를 업데이트하는 알고리즘으로 보통 k는 5에서 10의 값을 사용한다고 한다. k = 1인 경우 당연히 greedy choice가 된다.
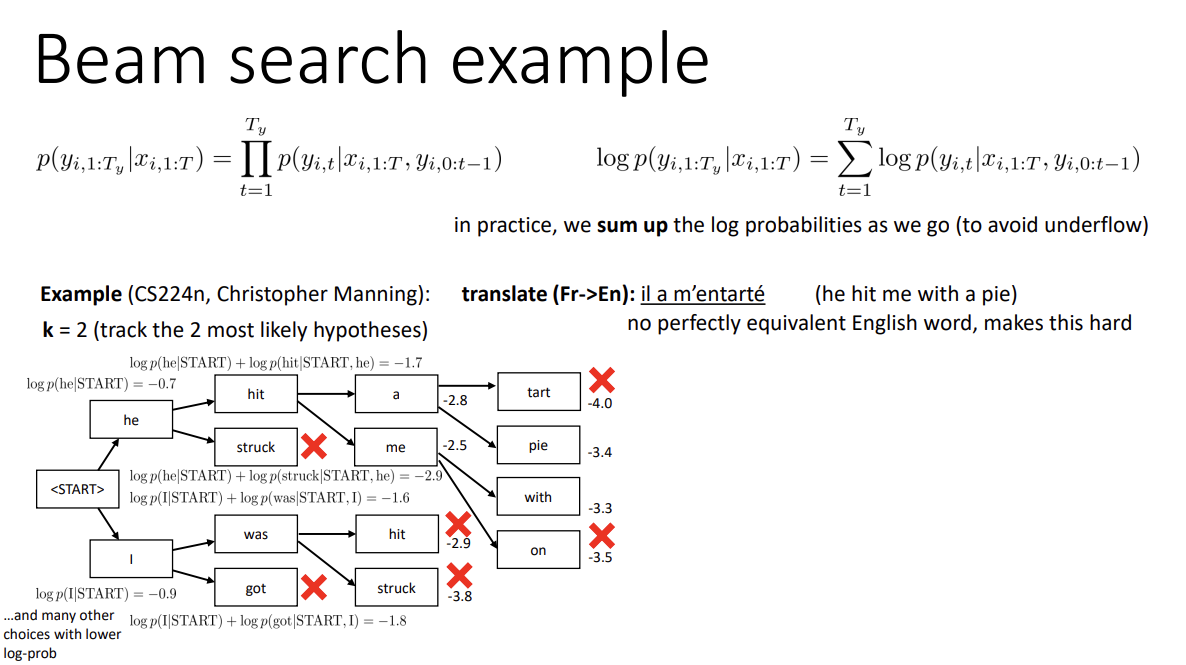
k = 2인 간단한 예시 이미지이다. 각 step마다 최대 2개까지의 최고 확률을 저장한다. 단 0과 1 사이의 수를 계속해서 곱할 시 underflow가 발생할 것이니 log를 취해 계산해준다. 이를 매 step마다 반복하며 branch를 정리한다.
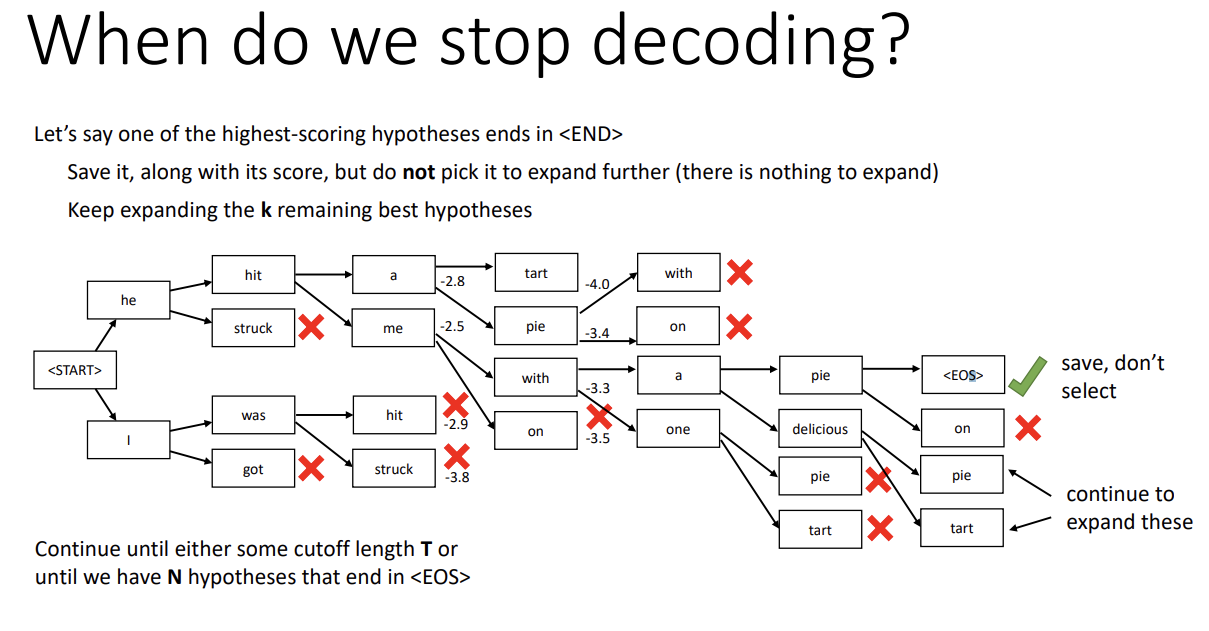
그런데 이 과정을 언제 멈출까? 만약 어떤 높은 score의 hypothesis에서 <EOS> token이 나올 경우, 그 정보를 저장하고 해당 branch에서는 더 진행하지 않는다. 이는 top k hypothesis에 포함되지 않으니, 남은 hypothesis 중 k개를 골라 과정을 계속 진행한다.
그리고 sequence의 길이가 특정 길이(T)가 되거나, <EOS>로 끝난 hypothesis가 특정 개수(N)개가 된다면 과정을 끝낸다.

또한 마지막에 sequence를 선택할 시, '그냥 log probability가 낮은 것을 고르면 되지 않을까?' 라는 생각이 들 수 있으나
음수를 계속 더해주는 특성상 sequence가 길어질수록 값이 작아지게 된다.
따라서, 전체 step 수로 log prob을 나눠 최종 값을 구해준다.

요약하면, 위와 같은 프로세스를 거치는 것이다.
다음 강에서 자세히 다룰 Attention에 대해 알아보자.
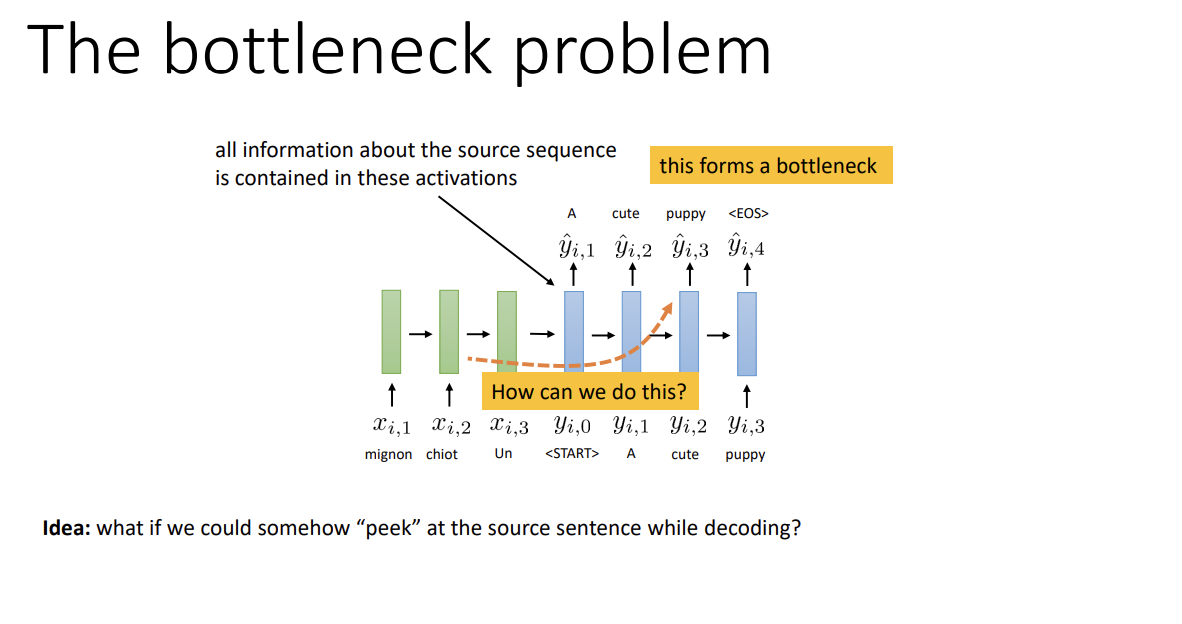
Sequence-to-sequence model은 input의 모든 정보를 encoder를 거쳐 decoder의 첫 input으로 압축한다. 그러나 input의 길이가 너무 길어지면 정보를 잘 압축하는 데 한계가 있기 마련이다. 이를 bottleneck problem이라고 한다.
즉 decoder는 encoder activation 외에는 원래 input에 대해 알 수가 없고, sequence가 길어질수록 encoder는 정확한 정보들을 activation으로 뽑기 위해 굉장히 신중해져야만 한다. 이는 매우 어려운 일이 되어간다.
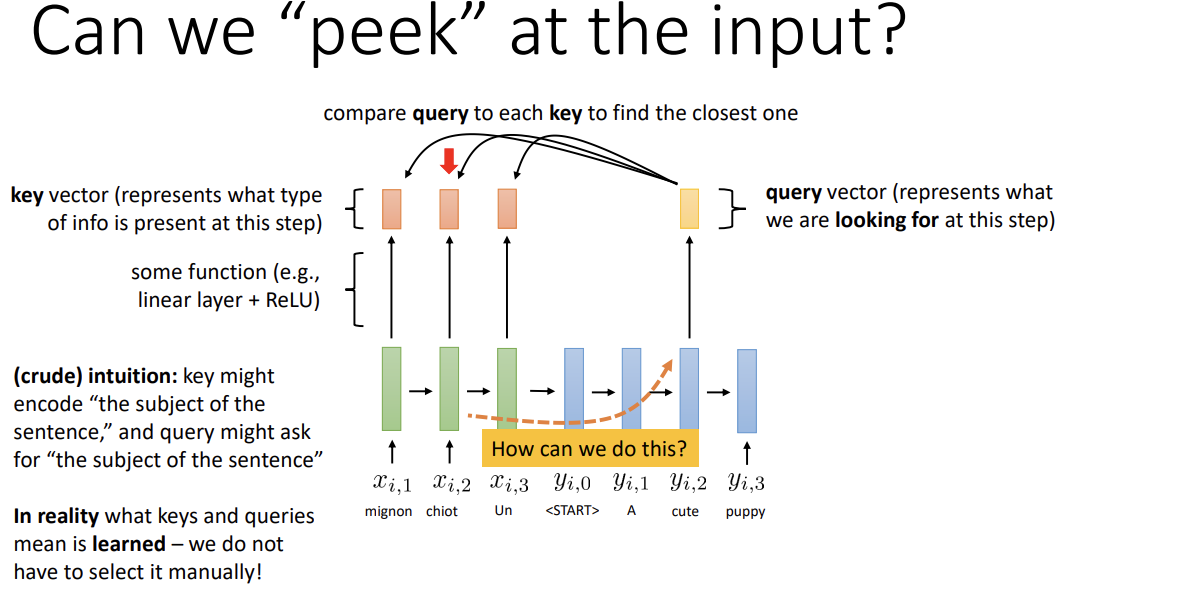
그래서, decoding 시 source sequence를 살짝 엿보는 방식을 통해 이를 보완한 것이 attention이다.이렇게 encoder가 지나치게 완벽할 필요가 없어지고 긴 sequence를 더 잘 처리할 수 있게 된다.
- Encoding 시 각 timestep마다 현재 정보를 묘사하는 작은 piece를 생성한다. 이를 key vector라고 한다.
- Decoding 시 같은 길이의 little vector를 뽑아낸다. 이는 현재 timestep에서 찾는 정보를 표현하는 것으로,
query vector라고 한다. - Query와 key를 비교해 가장 similar한 정보를 찾고, 그 시간대의 정보를 decoder로 보낸다.
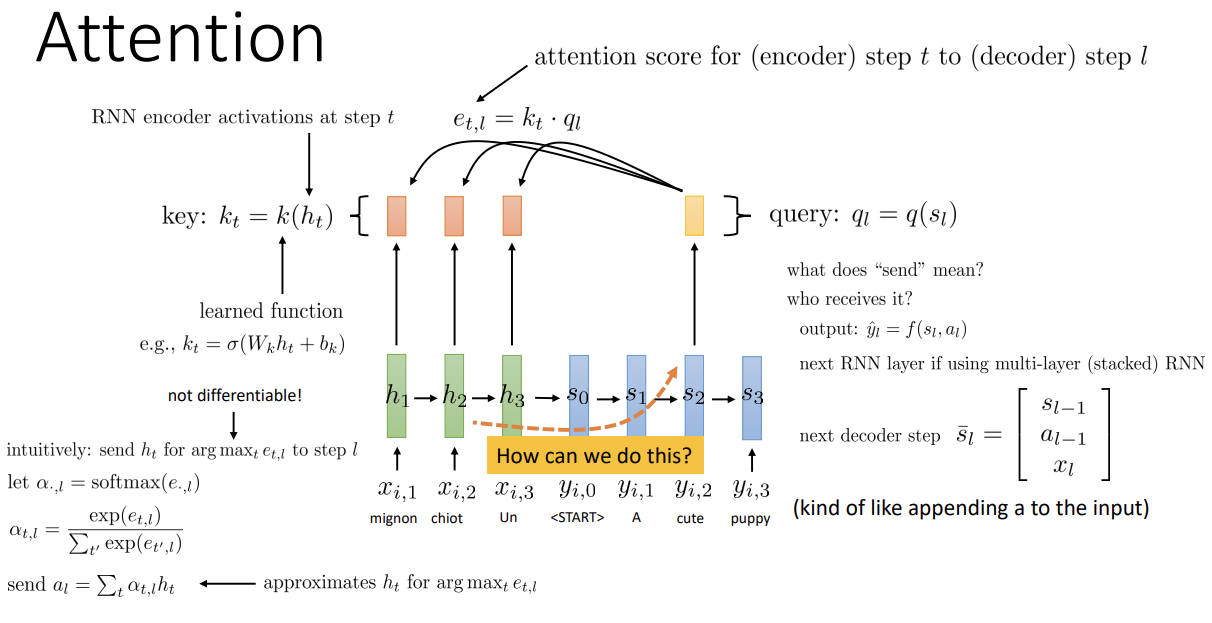
실제 구조와 식은 위 그림과 같다.
- h_t는 encoder의 hidden state, s_l는 decoder의 hidden state, k_t는 key, q_l는 query이다.
- 이때 k와 q는 각각의 hidden state의 function임에 주의한다. 이 둘은 learnable function이다.
- k_t(encoder step t의 key)와 q_l(decoder step l의 query)을 dot product해서 attention score e를 구한다.
- 기본 원리는 argmax를 통해 최대 score를 가지는 h_t를 decoder의 step l로 보내는 것이지만,
argmax는 미분이 불가능하기에 다른 방식을 사용한다.
decoder timestep l에 대한 모든 e를 각 timestep t에 대해 softmax 처리한 후
각각의 h와 weighted sum을 거친 값을 decoder로 보낸다.
이렇게 하면 softmax의 특성상 가장 값이 높은 score에서의 h_t가 가장 큰 비율을 차지하게 되어 해당 step의 많은 정보를 decoder에게 전달한다.

보내진 정보 a_l은 decoder의 여러 부분에서 사용될 수 있다.
output에 사용할 수도 있고, 다음 step의 input에 stack되기도 하고, multi-RNN 구조인 경우 다음 RNN의 input 중 하나로도 이용되기도 한다.
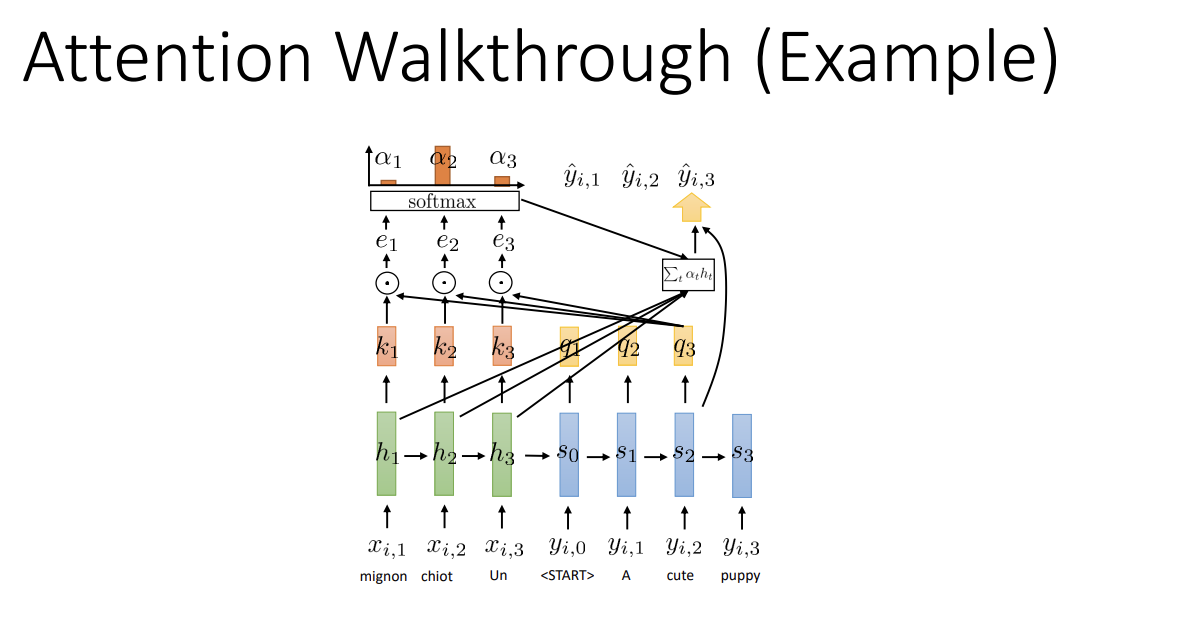
간단한 예시인데, decoder의 step 3에서 encoder의 key와 query를 곱해 e를 구하고, softmax를 거친 후 weight sum을 decoder에 전달하는 모습이다. 이 값은 decoder 해당 step의 output이 되는 듯하다.
몇 가지 variant가 있는데,

Linear transform일 수도 있다. 이 경우 weight matrix를 학습하면 된다.
두 개의 matrix를 학습해야 할 것 같지만, score를 구하기 위해 내적 시 하나의 matrix로 합쳐지므로 저 하나만 학습하면 된다.

또는 마지막에 h_t를 weighted sum하는 것이 아닌, learned function v를 이용해
v(h_t)를 weighted sum하는 경우도 있다.
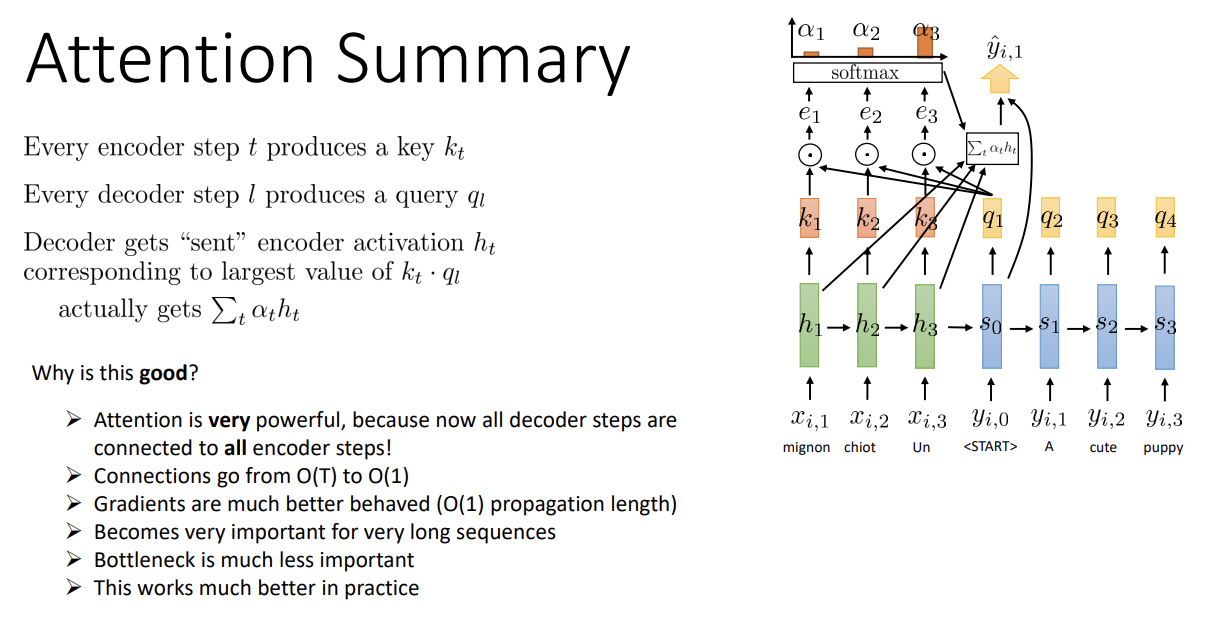
Attention을 마무리하며 요약해 보면,
각 encoder step마다 key k_t를, decoder step l마다 q_l을 구하고
step 간 score가 가장 큰 encoder step의 hidden state를 (실제로는 score에 따른 hidden state의 weighted sum을)
decoder step에 전달하는 것이 attention이다.
모든 decoder step이 모든 encoder step에 연결되어 있어 gradient 학습이 빠르다는 장점이 있다.각 step 간 connection이 하나이기 때문에 O(1)의 time complexity를 가지고, gradient 모양도 좋아진다.(LSTM과 비교하자면 LSTM은 gradient vanishing problem을 완전히 회피할 수 없다는 차이점이 있다)따라서 매우 긴 sequence에 대해 좋은 성능을 가지게 된다.
'ML, DL > CS182' 카테고리의 다른 글
| [CS182] Lecture 13 - Applications : NLP (0) | 2022.08.19 |
|---|---|
| [CS182] Lecture 12- Transformers (0) | 2022.08.14 |
| [CS182] Lecture 10 - Recurrent Networks (0) | 2022.08.11 |
| [CS182] Lecture 9 - Generating Images frome CNNs (0) | 2022.08.10 |
| [CS182] Lecture 8 - Computer vision (0) | 2022.08.10 |