2022. 8. 14. 22:44ㆍML, DL/CS182
(Self-attention) --> (Nonlinearity) -->
CS 182: Deep Learning
Head uGSI Brandon Trabucco btrabucco@berkeley.edu Office Hours: Th 10:00am-12:00pm Discussion(s): Fr 1:00pm-2:00pm
cs182sp21.github.io
지난 강의들에서 배웠던 RNN, attension을 바탕으로 이번 강의에서는 Transformer를 배운다.


11강에서 attention의 여러 장점들을 배우며 정말 좋은 구조임을 배웠다. 그러면, 굳이 recurrent connection을 사용하지 말고 기존의 RNN을 attention만 사용한 모델로 만들 수는 없을까?
Decoder에서 나중 hidden state가 이전 hidden state를 확인할 수가 없어, 이 점을 우선 고쳐야 한다.

먼저 self-attention을 살펴보자. 각 hidden state 간 연결이 없어 recurrent model은 아니지만,
각 layer마다 같은 weight를 여전히 사용하고 있다.
이제 encoder와 decoder가 같이 있는 것처럼 매 step마다 key, query를 모두 계산하고
이전(attention)에선 value function이 identity였지만 이제는 어떤 함수를 사용한다.
각 step에서는 다른 모든 step의 key에 접근이 가능하게 된다. (information을 time step에 관계없이 합친다는 느낌)
Attention score를 구하고 이를 weighted sum해서 a_l을 구하는 과정은 attention과 같다.

이러한 self-attention layer를 쌓아서 모델을 구성할 수 있다.
이전 self-attention layer의 output은 다음 layer의 input이 된다.

이제 self-attention을 사용해 transformer를 만들 수 있다.
그러나 이 모델이 잘 작동하게 하려면 추가로 개발해야 할 것들이 있다.
- Positional encoding
Basic self-attention에는 위치 정보가 없기 때문에, 한 sequence의 element들은 순서 상관없이 처리될 수 있다.
즉 sequence의 순서를 바꿔도 같은 답이 나올 수 있고, NLP 등에선 큰 문제가 될 수 있다.
이를 해결하기 위해 위치 정보를 추가해주는 것이 positional encoding이다. - Multi-head attention
한 layer가 query를 통해 어떤 step의 정보를 물어본다. 그러나 여러 지점에 동시에 집중할 필요가 있다면 어떨까?
예를 들자면 문장을 분석 시, 주어, 동사, 목적어 등에 동시에 집중하고 싶을 수 있다.
이 경우 하나의 head로는 부족하므로, multi-head를 두어 multiple position에 querying할 수 있게 한다. - Adding nonlinearities
지금까지는 layer들에서 이뤄지는 연산이 matrix multiplication, weighted sum 등으로 linear했다.
그러므로 nonlinearity를 추가해준다. - Masked decoding
Self-attention으로 정보를 확인할 시 과거, 미래 정보를 구별할 수 없다.
첫 번째 step에서 100번째 step의 정보를 보고 예측할 수는 없는 노릇이니,
현재 step보다 과거에 있는 step만 확인하도록 해야 한다.

1. Positional encoding
Naive self-attention은 문장을 순서 없이, 위 이미지에 나온 것처럼 인식한다.
그렇게 된다면 임의의 순서로 문장이 섞일 텐데, 의미 없는 문장이 되거나 의미가 변할 수 있다.
때문에 문장의 위치 정보를 추가해준다.

Naive한 아이디어는, input에 위치 정보를 나타내는 t를 concatenate해 주는 것이다.
그러나 여기서는 relative position이 중요하지, absolute position이 중요한 것이 아니기에 그렇게 좋은 방법은 아니다.
Relative position이 비슷하다면 positional encoding을 비슷하게 하고자 한다면, 어떻게 해야 할까?
Frequencey-based representation을 사용해서 나타낼 수 있다. p_t의 처음 부분 entry들은 frequency가 높고, 나중 부분은 frequencey가 상대적으로 작아진다. (차원이 증가할수록 주기가 조금씩 늘어남)
(사실 이 부분을 잘 이해하지 못해서 아래의 블로그를 참고하였다.

또는 각기 다른 time step마다 달라지는 p_t를 학습하는 방법도 있는데, bias처럼 작용한다.
조금 더 유연하나 최대 sequence length를 정해야 해서 조금 복잡하다. (sin/cos는 t의 값에 대입만 하면 된다)

이를 적용하는 방식은 보통 2가지인데
간단하게는 concatenate하는 것이고, 더 자주 사용되는 방법은 input을 embedding한 뒤 p_t와 더해주는 것이다.
이때 embedding function은 학습시켜야 한다.
2. Multi-head attention

두 번째로, multi-head attention이다.
Attention score는 두 가지 다른 것에 집중하고 싶음을 알리기 어렵고,
output a_l은 softmax로 인해 가장 비중이 높은 한 가지 값에 의해 값이 결정되는 경향이 있다.

그래서 각 layer마다 여러 개의 key, query, value를 가지는 것이 multi-head attention이다.
이때 attention score, weighted sum 등은 각각의 head마다 독립적으로 계산해야 한다.
그렇게 해서 나온 a_l, i를 쌓아서 최종 output을 만든다.
보통 큰 모델에서는 8개의 head 정도면 잘 작동한다고 한다.
3. Adding nonlinearities
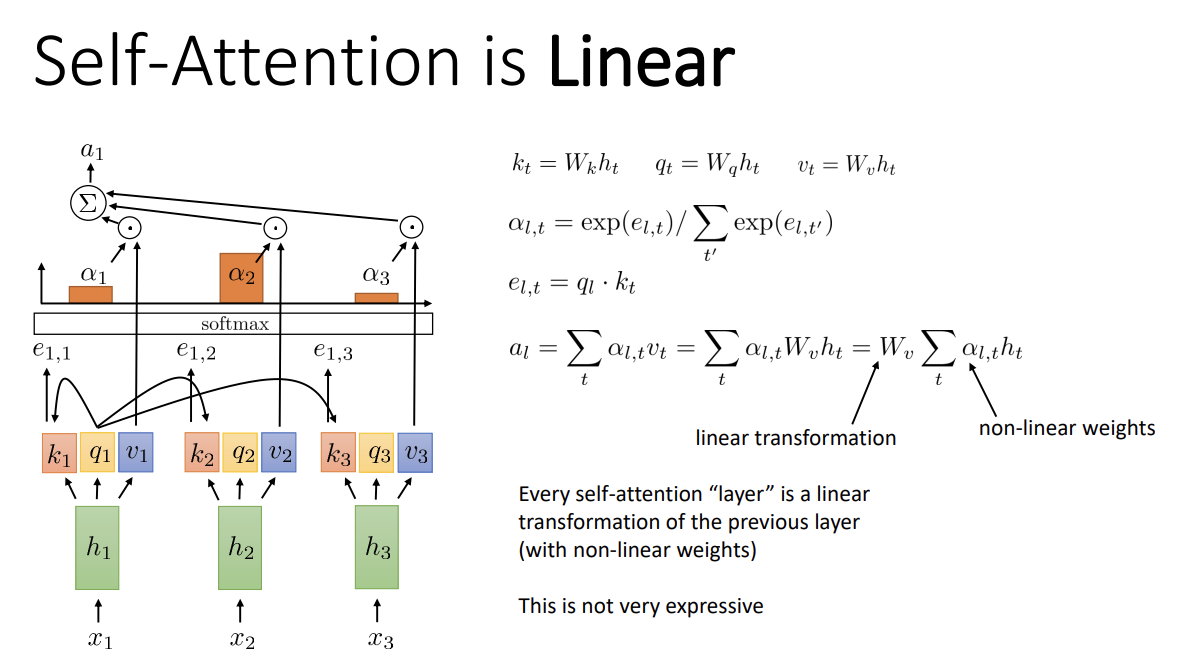
위 식에서 볼 수 있듯, a_l은 hidden state h_t에 linear하다.
이는 그리 좋지 않기에 따로 non-linear layer가 필요하다.

이를 위해 "self-attention layer"의 output을 non-linear (learned) function에 통과시킨다.
각 output마다 independent하게 통과시킨다. 이를 position-wise feedforward network라고도 한다.
(Self-attention) --> (Nonlinearity) --> (Self-attention) --> (Nonlinearity) --> .... 라고 생각하면 된다.
4. Masked decoding

매 query는 모든 step의 key 정보를 확인할 수 있어 현 시점보다 미래의 정보를 볼 수 있는 상태이다.
위 graph에서 첫 step의 output의 경우를 보면 2번째, 3번쨰 step의 key를 참고하게 되고, 그렇게 나온 output은 2번쨰, 3번째 step의 input으로 활용된다. 따라서 test 시, 2번째와 3번째 step의 input은 1번쨰 step의 output에 의해 결정되나 그 output을 구하려면 2번째와 3번째 step의 input이 필요한 모순적인 상황이 발생한다.

그래서 나온 것이 masked attention이다. 현 시점보다 과거에 집중하는 것은 가능하나, 미래 정보를 보는 것은 불가능하게 하는 것이다.
따라서 이제 attention score는 encoder step t에 관해 나뉘게 된다.
실제 개발 시에는 infinitity가 껄끄러우니, decoder step l보다 t가 큰 경우 exp를 취한 값을 0으로 만들어버린다.
요약하자면,
- Self-attention을 이용해서 기존 recurrent model을 대체할 수 있다.
- 이를 위해 nonliear position-wise feedforward network를 self-attention layer 대신 사용한다.
- Input의 위치 정보를 알 수 있게, positional encoding을 사용한다.
- Input sequence의 여러 위치에 동시에 attention이 가능하도록 multi-head attention을 사용한다.
- Output을 실제로 사용할 수 있게 decoding 시, 미래 정보에 접근하지 못하게 masked attention을 사용한다.

앞서 본 4가지를 사용해 succesive self-attention, pointwise nonlinear layer를 sequence에 사용한 모델을 transformer라고 한다. 다음 강의에 나올 BEFT, GPT 등의 language model 들이 이 transformer를 활용한 유명한 모델들이다.

위는 classic transformer의 구조이다. 왼쪽은 encoder part, 오른쪽은 decoder part이다.
각 attention이 끝나고 point-wise nonlinear network가 사용되고, decoder에는 masked self-attention이 있다.
주목할 점은 앞서의 self-attention과 조금 달라 보이는 cross attention layer인데,
같은 sequence의 다른 timestep들을 살펴보는 self-attention과 다르게
cross attention은 대응하는 encoder layer의 timestep을 본다.
따라서 decoder의 반복되는 layer 수는 encoder보다 2배 많아지게 된다.

마지막으로 layer normalization을 배운다.기존의 batch normalization은 굉장히 좋은 방법이다. 그러나 길이가 일정하지 않은 sequence들에 적용하기에는 무리가 있다.그래서 batch normalization과 비슷하지만 batch 간 normalization을 하는 것이 아닌,data sequence 각각에 대한 mean과 variance를 구해 normalization을 하는 것이 layer normalizaiton이다.
이제 이것들을 모조리 합쳐 보자...

- Encoder part
Input은 l-1 block의 output이다. 첫 번째 block에스의 input은 embedding vector + positional encoding이다.
Input은 순서대로 multi-head attention, add+layernorm, point-wise nonlinearity feedforward, add+layernorm
을 거친다.
Layernorm 시 해당의 input을 더해주는 이유는 각 layer에서 modification이 일어나고, gradient behavior를 좋게 하기 위해서이다 (residual connection과 유사) - Decoder part
Encoder와 대체로 유사하지만 mask attention을 사용해 한 번에 한 position을 decode하고,
cross-attention layer이 있다.
대응하는 encoder part의 output과 attention을 거쳐 output을 생성해낸다.
Cross-attention 다음의 add+layernorm 시에는 self-attention과 cross-attention의 output을 더한 것을 normalize.
왜 transformer라는 모델이 그렇게 좋을까?

Transformer의 attention의 time complexity는 O(n^2)이지만, 강의에서는 dot product에 드는 시간은 짧고 그 외 다른 부분에서 시간이 걸린다고, quadratic이지만 앞의 계수가 작다고 생각할 수 있다고 했다. 때문에 실제 시간은 꽤 빨라 단점이 어느 정도 완화된다고 한다.
또한 개발하기가 복잡하다는 단점도 존재한다.
그러나, 긴 connection에 대해 더 잘 작동하고 parallelize하기 더 쉬우며,
일반적인 RNN보다 훨씬 깊게 모델을 구성할 수 있다는 장점이 있다.
이 장점들에 힘입어 RNN과 LSTM보다 월등히 잘 작동하고 큰 성능 향상을 이끌어낸 모델이다.
'ML, DL > CS182' 카테고리의 다른 글
| [CS182] Lecture 17 - Generative modeling (0) | 2022.08.25 |
|---|---|
| [CS182] Lecture 13 - Applications : NLP (0) | 2022.08.19 |
| [CS182] Lecture 11 - Sequence to Sequence Models (0) | 2022.08.13 |
| [CS182] Lecture 10 - Recurrent Networks (0) | 2022.08.11 |
| [CS182] Lecture 9 - Generating Images frome CNNs (0) | 2022.08.10 |