[CS182] Lecture 13 - Applications : NLP
CS 182: Deep Learning
Head uGSI Brandon Trabucco btrabucco@berkeley.edu Office Hours: Th 10:00am-12:00pm Discussion(s): Fr 1:00pm-2:00pm
cs182sp21.github.io

이번 강의에서는 이전까지 배운 RNN 관련 아이디어가 NLP 분야에서 어떻게 쓰이는지에 대해 간략히 배운다.
물론 그 범위가 굉장히 넓기 때문에, 강의 내애선 unsupervised pre-training에 초점을 맞춰 살펴본다.

딥러닝은 data의 양이 많을 때 잘 작동한다. 또한 모델의 크기는 dataset이 커질수록 증가하게 된다.
Text data를 생각해보자. 우리 주변에는 말 그대로 텍스트가 넘쳐난다. 지금 쓰고 있는 강의 정리본도 텍스트이고, 옆에 있는 책, 신문 등이 모두 텍스트이다. 그러나 특정 용도로 데이터를 사용하기 위해선 그에 맞게 labeling이 되어 있어야 한다. 안타깝게도 주변의 거의 모든 text data는 unlabeled data이다. 이를 어떻게 잘 활용할 방법이 없을까?

우리는 unlabeled data로 data의 representation을 학습할 수 있다. 예를 들자면, english data로부터 언어의 representation을 학습해, french로 다시 번역하는 식으로 이 representation을 활용할 수 있다.
즉 unlabeled data는 representation learning에 사용 가능한데, 문제는 이 representation을 어떻게 나타내냐이다.
이 representation의 spectrum이 위 이미지에 나타나 있다.
- Local non-contextual representations의 경우, 각 단어가 쓰이는 문장에 관계없이 나타내는 representation이다.
King이라는 단어와 president라는 단어는 어느 정도 유사한 의미를 가지고 있다. 그러나 이는 문장에 따라 달라질 수 있다.
He is the president of that group과 He is the king of that group에서의 president와 king은 다른 뜻이 된다. - Global context-dependent representations는 문장 또는 문단 전체를 읽어 해당 token이 그 안에서 쓰이는 의미를 담는 것이다. 문맥을 고려한 의미를 담을 수 있다.

간단한 representation method로는 one-hot vector가 있다. 그러나 이 방법은 단어 간 relationship, similarity를 반영하기 힘들다는 단점이 있다. 나쁘지 않지만, 좋지도 않은 표현이다.
고로 더 의미있는 representation을 사용 시, learning downstream task가 더 쉬워질 것이다.

아니면 word embedding을 학습하게 할 수도 있다. 기본적으로, 단어의 의미는 그와 가까이 있는 다른 단어들에 의해 결정될 수 있다는 아이디어에서 출발한다. 또한 어떤 두 단어를 문장에서 서로 바꿔서 사용해도 의미가 통한다면, 그 두 단어는 더욱 비슷하다고 생각할 수 있다.

그러면 단어의 embedding value를 통해 단어의 주변 단어를 예측할 수 있을까?
특정 단어 주위의 몇몇 단어들을 context word라고 한 뒤, center word와의 일종의 유사성을 softmax를 통해서 취한다.
이 확률이 가장 높은 단어의 embedding vector를 고르는 방법으로 훈련시킨다.
이때 가능한 context word, center word 간의 모든 조합을 살펴보니 vector의 수가 매우 많고 high-dimensional함을 알 수 있다. 이는 그렇게 반가운 일은 아니다.

word2vec이라는 representation 방식이 이 아이디어 기반이다.
앞서 단어 수가 굉장히 많아져, softmax를 취할 때의 분모를 계산하는 데 시간이 너무 오래 걸린다는 문제가 있었다.

그러면 대신, 이 단어에 대한 probability를 판단해 참 / 거짓으로 분류해주는 binary classification으로 만들어주자.
이제 2개의 단어를 골라서, output이 참인지 거짓인지 판단하기만 하면 된다. 마치 logistic regression처럼 sigmoid를 사용해주면 된다.
다만 이것만 할 경우 또 다른 문제가 발생할 수 있다. 모든 u, v가 같고 entry의 값이 매우 큰 벡터들이라고 생각해보자. 그러면 <u, v>의 값이 굉장히 큰 양수가 될 것이고 sigmoid prob은 1에 가까워질 것이다. 모든 단어가 유사한 것과 같아진다.
즉 비슷한 단어는 맞게 해 주지만 비슷하지 않은 단어를 틀리게 하지는 않는다.
따라서 context word가 틀린 단어일 경우에 대한 확률을 추가해 최종 objective function을 만들어준다. 이때 틀린 단어들은 사전에서 임의로 몇 개의 단어를 뽑아 진행한다.

위의 식들로 정리할 수 있다. 실제 사용 시에는 batch를 사용해 gradient descent를 진행하므로, random word batch 내에서 context와 negative word들을 랜덤으로 고른다.
몇 가지 예시들을 보겠다.

위에서 "woman", "man" 간의 차이는 "aunt", "uncle"의 차이와 비슷한 것을 볼 수 있다. 다른 말로 하면 "uncle" 단어 vector에 "woman" - "man"을 더하니 "aunt"가 된 것으로도 볼 수 있다. 이를 단어 간 algebric relationship이 있다고 하는데, 이는 이상적인 상황으로 발생하지 않는 경우가 더 많다고 한다.

표의 왼쪽에 relationship의 종류가 있고, word2vec을 통해 그러한 관계의 단어 pair들을 나열한 것이다.

Word embedding은 각 word에 vector를 할당해준다. 안타깝게도 이 vector는 word가 문장 내에서 또 다른 의미로 사용된다고 해서 변하지는 않는다. 이 representation을 context에 대해 배우게 할 수 있을까?
Language model을 훈련시킨 뒤 문장에 관해 돌리고, 그때 나온 hidden state를 representation으로 사용한다면 (최소한) 문장 내 이전의 단어들을 고려한 representation이 생성될 것이다.

이 아이디어를 사용해 만들어진 모델들이 있는데, Sesame Street에 나오는 캐릭터들의 이름을 가지고 있다.
ELMo는 context-dependent embedding에 사용되는 양방향 LSTM 모델이고, BERT는 transformer language 모델이다.
BERT가 더 효율적이고 좋지만 우선 ELMo부터 살펴보기로 하자.

ELMO에선 forward LSTM만 사용할 경우 현재 step 이후 단어는 못 보고 예측한다는 문제점을 해결하기 위해, forward와 backward 2개의 모델을 따로 사용하였다. Backward LSTM에선 뒤집은 문장이 input으로 들어가는 것이다.
따라서 hidden state는 forward information과 backward information을 모두 가진다. 과거와 미래 정보 모두를 고려한다.
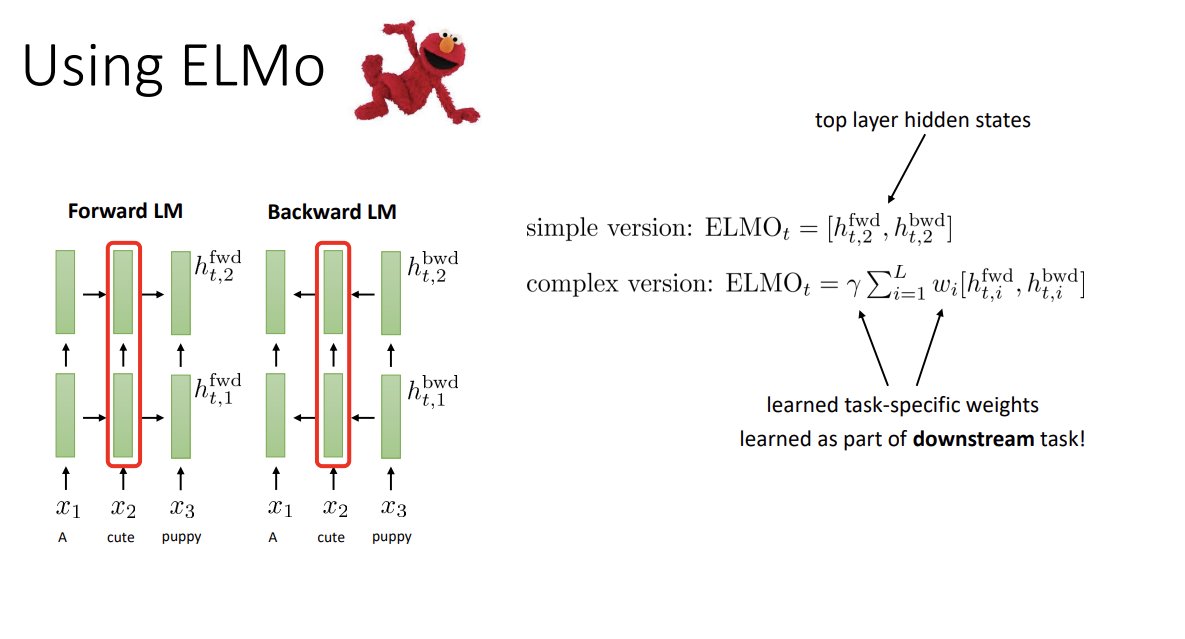
간단한 버전의 ELMO를 사용 시에는 가장 위 layer의 hidden state를 사용한다. 다음 단어를 예측하는 곳에서 가장 가깝기 때문이라고 한다. 복잡한 버전의 경우 모든 layer의 hidden state를 weighted sum해서 사용한다. 이 weight는 learnable하다.

둘 중 뭐가 되었든 간에 모델을 사용하고 나면 특정 문장에서의 단어에 대한 ELMo representation을 얻게 된다. 그 representation을 원래 input이였던 word embedding 등에 concatenate한 뒤 새로운 input으로 사용해, 본래 목적에 사용하는 것이 ELMo를 사용하는 주된 방식이다.

정리하면, unlabeled data에 대해 양방향 LSTM 모델을 훈련해서 context-based word representation을 생성하고, 기존 word embedding에 concatenate해서 기존 downstream task에 사용한다.

다음으로 BERT에 대해 알아보자. 하나의 transformer를 사용한 모델이다.

앞에서 썼던 LSTM 대신 양방향으로 transformer를 사용하면 쉽게 대체가 가능할 것이다.
그러나 그냥 하나만 사용할 수는 없을까? 만약 그렇다면 decoder part를 사용하게 된다. 그러나 여전히 directional model이다.
또한 encoder가 없으므로 cross attention을 진행하지 않는다.

그리고 원래는 사용했던 masking을 제거해서 과거와 미래를 동시에 고려할 수 있게 한다.
그러나 잘 생각해보자. 학습 과정에서 input으로 한 칸 shift된 sequence를 받아 처리하게 되는데, 이때 timestep t의 output이 timestep t+1의 input과 같게 된다. 따라서 모델은 오른쪽의 단어를 답으로 내도록 학습하게 되고 이는 적절치 않다.

그래서 BERT에서는 input sequence에 random masking을 취한다 (output에는 안 함). 모델은 빈칸이 주어진 문장에서 그 빈칸을 적절히 채우도록 학습되고, 이 과정에서 transformer를 통해 해당 단어의 context-dependent representation을 학습할 수 있을 것이다. 이를 통해 BERT를 bidirectional하게 만들 수 있다.
Masking 비율은 보통 15%로 설정한다고 한다.

BERT를 훈련하는 과정은 앞서 말했던 것처럼, 각 step마다 일정 확률로 token들을 masking한 뒤 예측하게 한다.
Input은 pair of sentence라고 하는데, 많은 downstream task가 두 문장에 대해 이뤄졌기 때문이다.
이때 두 문장의 순서를 50% 확률로 바꾸고, 첫 token은 [CLS]라는 특수한 것으로 설정한 뒤 첫 output은 prediction을 하도록 한다. 뭘 예측하냐면, 문장 순서가 첫 문장 - 두 번째 문장인지 아니면 그 반대인지를 일종의 binary classifier로 예측한다.
이를 하는 이유는 sentence-level representation을 표현하기 위해서이다. Word-level representation은 각 position의 output을, sentence-level representation은 첫 position output을 가져다 쓰면 된다.
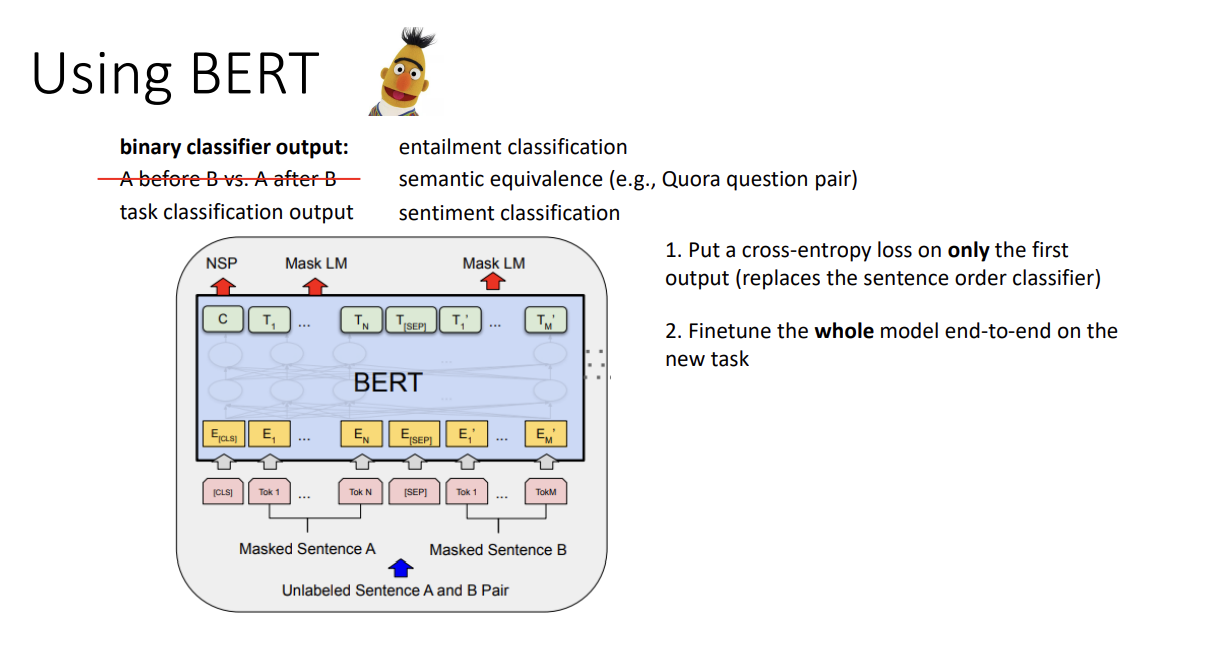
첫 부분의 binary classifier에 내가 원하는 task에 대한 classifier를 넣고 새로운 loss를 넣는 것으로 BERT를 활용할 수도 있다.
(Entailment classification, semantic equivalence, sentiment classification...)
그렇게 하려면 우선 위에서 배운 일반적인 BERT (language model + a-b / b-a ppredictor) 를 훈련한 후,
결과로 나온 model의 첫 position의 loss를 내가 원하는 classification loss로 대체한다 (그리고 다른 모든 loss를 버린다는 것 같다). 그리고 새로운 task에 대해 계속 train해준다.

Sentence pair나 single sentence에 대한 classification을 수행하게 할 수도 있고.
문단을 입력으로 준 뒤 질문에 대한 답이 문단의 어디에 있는지 강조해 주도록 할 수도 있고.
각 position마다 특정 label을 붙여 줄 수도 있다.
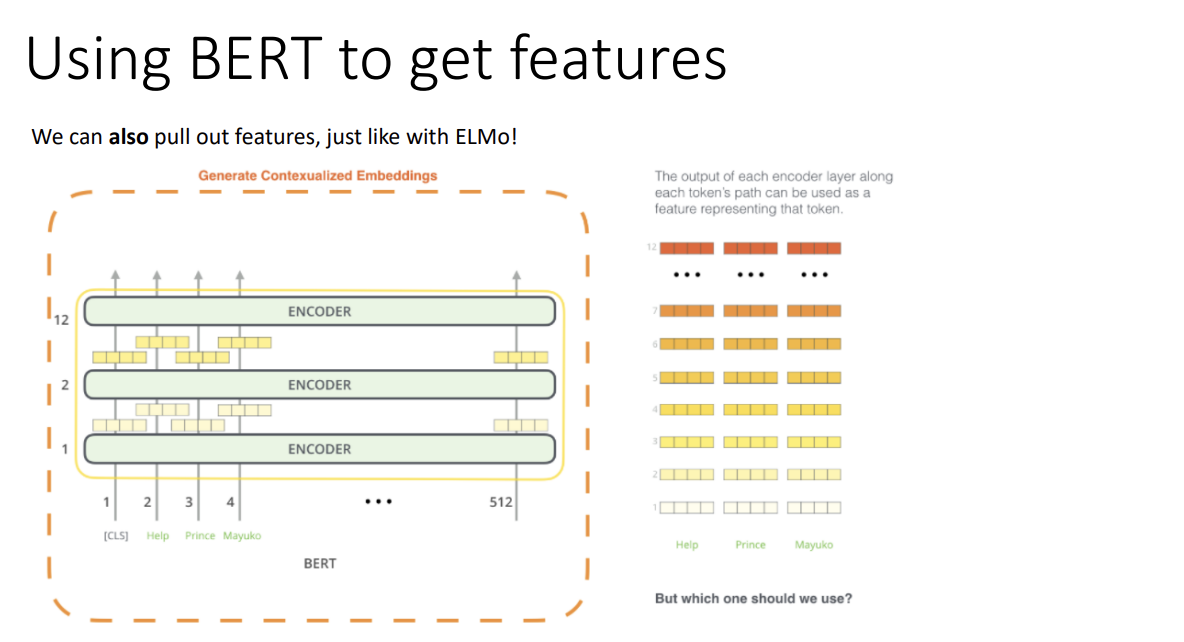
이제, BERT를 사용해 feature를 추출해 보자.
그런데 모델의 크기가 커 12개의 transformer block이 있는데, 무엇을 사용해야 할까?
BERT의 성능 자체가 좋아 보통 어지간하면 좋긴 하나, 조금 자세히 살펴보자.
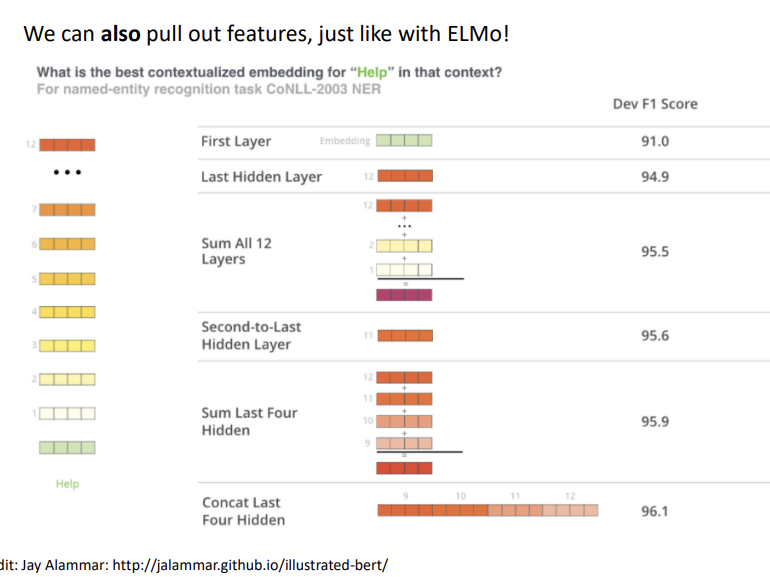
단일 layer의 hidden state를 사용하는 경우는 가장 마지막의 것을 사용하는 것이 제일 좋았고,
그보다는 layer들을 합하거나 concatenate하는 방식이 더 좋게 나왔다.
물론 위에서 보이다시피 성능이 다들 좋다. 따라서 bidirectional transformer를 사용해 pre-training하는 것으로
downstream task에서 이전과 성능의 차이를 크게 낼 수 있게 되었다.

마지막으로 GPT에 대해 알아보겠다.
앞서 배운 BERT는 bidirectional transformer model이다. One-directional transformer model의 경우 보통 BERT보다 좋지 않지만, generation task에 대해서는 BERT보다 훨씬 좋다. BERT는 빈 칸을 채우는 것이지, step마다 token을 생성하는 것이 아니기 때문이다. GPT는 transformer의 decoder를 사용하고 따라서 cross-attention이 없다. 또한 많은 layer로 이루어져 있다.Self-attention machanism을 통해 long-term structure, connection이 생성된다.

이것이 GPT-2를 사용해 input에서 긴 글을 생성해 낸 모습이다. 특히 인명과 지명 등을 생성해낸 점이 흥미로웠다.

위에서 살펴본 3개의 pretrained language model을 요약하면 이와 같다.
BERT는 representation에, OpenAI GPT는 generation에 강점이 있고, ELMo는 좋은 representation을 만들어내나 BERT가 상위 호환이다.

강의를 요약해보자면,
Language model은 unlabeled dataset을 사용해서 pretrain 될 수 있다.
이때 단어의 representation을 먼저 학습하는데, 이는 context에 따라 변할 수 있다.
조금 더 나아가서, sentence representation 또한 얻을 수 있다.
이 representation들을 추출해서 word embedding 대신 사용할 수도 있고, pretrained model 자체를 또 다른 downstrearm task에 사용할 수도 있다.