[CS182] Lecture 9 - Generating Images frome CNNs
CS 182: Deep Learning
Head uGSI Brandon Trabucco btrabucco@berkeley.edu Office Hours: Th 10:00am-12:00pm Discussion(s): Fr 1:00pm-2:00pm
cs182sp21.github.io

이번 강의에선 CNN을 활용해 이미지를 생성하는 것에 대해 다룬다.

실제 네트워크가 무엇에 집중하는지를 확인하고 잘 작동하는지를 파악하기 위해선 CNN이 실제로 이미지를 어떻게 관찰하는지에 관심을 가질 필요가 있다.
그 전에, 우리의 뇌가 이미지를 어떻게 인식하는지에 대해 먼저 보자면,
뇌가 이미지를 어떻게 인식하는지에 관한 연구가 고양이를 대상으로 이뤄진 적이 있는데
뇌의 neuron이 각기 다른 방향의 edge들에 반응한다는 결과가 나왔다.

CNN이 실제로 보는 것을 알아보려면, 뇌에서 뉴런의 역할을 하는 필터를 확인해 보면 될 것이다.
첫 layer의 경우 필터의 channel이 input image와 같으니 시각화가 가능한데, 앞서 본 뇌에서와 같이 oriented edge들을 감지해서 활성화하는 것으로 보인다.
그러면 그 이후는 어떨까? channel이 달라 첫 layer처럼 filter 그 자체를 시각화할 수는 없는데, 어떻게 할까?
이는 이미지의 어떤 부분이 뉴런을 강하게 활성화시켜 자극을 주는지를 확인해서 시각화가 가능하다.
(e.g. 5번째 layer의 27번째 필터를 잘 활성화시키는 location 찾기)
자세한 방법을 알아보자.

첫 번째로, 특정 unit을 가장 많이 활성화시키는 부분을 찾되, 앞선 강의들에서 나온 sliding window를 사용해 patch들 중 가장 큰 활성화 값을 가진 걸 확인하는 방법이다.
위 사진은 patch들이 겹쳐 있어 헷갈리나, 오른쪽 눈이 중심이 되는 patch가 가장 값이 높다. 즉 여기서 확인 중인 필터는, 눈을 관찰한다고 할 수 있다. (왼쪽 눈의 box 역시 값이 두 번째로 높다)
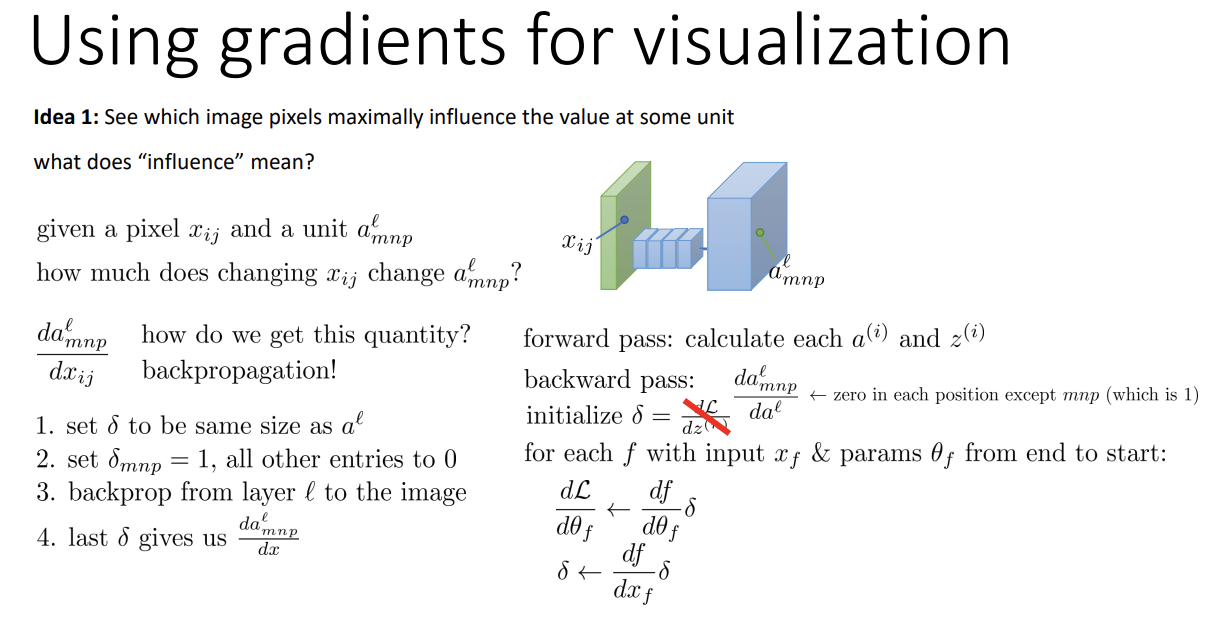
또 다른 방법으로는 gradient를 활용하는 것이다. 특정 unit에서, 어떤 pixel이 최대의 influence를 가지는지 확인하는 것이다.
그런데 influence가 무엇일까? 어렵지 않다. 어느 한 픽셀의 값이 조금만 변해도 unit에서의 활성화 값이 크게 변한다면 influence가 큰 것이라고 생각할 수 있다. 즉, gradient와 같고, 위와 같이 backpropagation을 통해 구할 수 있다.

이를 실제로 수행하면 위의 왼쪽 아래의 사진처럼 나온다. 뭔가 불분명하고 노이즈가 낀 듯하다.
이를 guided backpropagation을 사용 시, 더욱 명확하게 visualize가 가능하다.

일반적인 backpropagation 시 다른 unit들에게 positive한 영향, 또는 negative한 영향을 받을 것이고 positive 혹은 negative gradient가 추가된다.이때 negative한 influence는 복잡하기에, 이 복잡한 내용을 지워줌으로써 보다 명확한 visualize가 가능하다고 한다.즉 backpropagation 시 ReLU를 gradient에 추가해주는 것이다.
이전엔 단지 gradient를 계산했다면, 이제 그 정보를 바탕으로 직접 img를 modifying해서
특정 unit을 최대로 활성화시키는 이미지를 직접 만들어 visualize한다.

이렇게 이미지의 pixel 값을 activation이 커지는 방향으로 증가시켜 나간다.

문제는 이걸 naive하게 사용할 시, 특정 unit에 대해 값을 지나치게 활성화시켜
"crazy image"가 나올 수 있다는 점이다.
때문에 이를 예방하는 regularization term을 추가한다. 간단하게는 L2를 사용하면 된다.
한 번 class들에 대해 visualize를 해 보자.
특정한 class에 대한 activation 값이 가장 높게 하는 x를 구하면 된다.

주의할 점으로는 확률 값의 최대화가 아닌, softmax 투입 전의 activation 값의 최대화라는 것이다.
그렇지 않으면 확률 값이 지나치게 증가해 crazy image가 나온다고 한다.
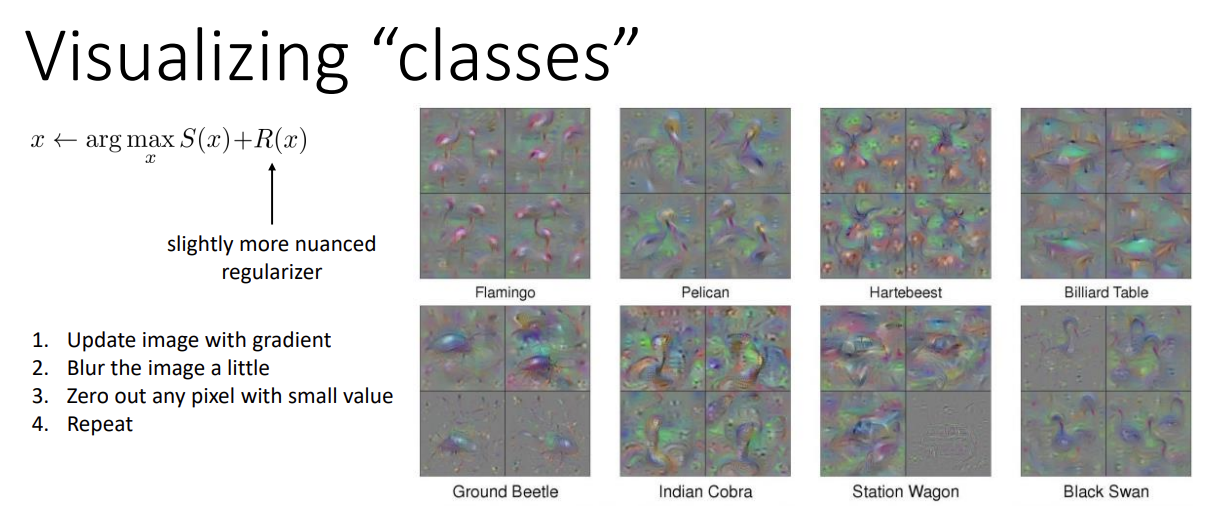
과정은 다음과 같다.
- Image를 gradient를 사용해 업데이트한다.
- 정확도를 소폭 감소시켜 crazy image를 방지하기 위해 살짝 블러 처리를 한다.
- Little noise가 network를 혼란시키는 것을 방지하기 위해, 어느 정도 작은 값들은 0으로 만든다.
- 1~3을 반복한다.
이 방식을 이용해 몇몇 class를 visualize한 예시들을 위 이미지에서 볼 수 있다. 원본 class와 비슷한 부분이 꽤 있다.
Filter visualizing 방법들을 사용해 image 자체를 transform 시킬 수도 있다.
예를 들면 다른 그림에서 feature를 추출해 다른 image를 변형시키는 것이다.
먼저 DeepDream에 대해 알아보자.

직관적으로는, 하늘의 구름들이 간혹 개나 코끼리같은 동물의 형상을 띄고 있을 때가 있지 않은가? 이런 특이한 pattern을 찾는 것과 같다.

Layer 하나를 고르고, backpropagation 시 delta가 그 layer에서의 activation과 같도록 해서 activate된 특정 패턴이 더 잘 드러나도록 하는 것이다.

코드는 위와 같다. dx가 특정 layer에서의 x로 대체되는 것을 볼 수 있다.
Jitter regularizer는 이미지가 보다 natural하게 보이도록, crazy image가 되지 않도록 규제해주는 역할을 한다.

예시 이미지는 다음과 같다. 하늘 사진에서 강아지 pattern을 극대화시킨 모습이다.

이런 사진들도 생성해낼 수 있다는 것이 신기했다.
이제 Style Transfer를 알아보자.
한 image에서 feature를 뽑아내는 것 말고, 다른 image의 feature를 닮게 하는 것은 어떨까?

이렇게 간달프 사진이 피카소 그림의 feature를 닮도록 하는 것이다.
Image에서 style을 추출하고, 다른 image에서 content 정보를 얻은 뒤 style을 content의 spatial information과 결합시키면, style을 반영한 새로운 이미지가 등장한다.(Style은 feature 간의 관계들이고, content는 그 feature들의 공간적인 정보이다)
자, 이를 위해선 style을 quantify해야만 한다.보통 lower layer는 simpler pattern을, higher layer는 elaborate pattern을 나타낸다.Style 추출 시엔 이 pattern들이 어디 있는지는 별로 중요하지 않다. 다만 어떤 feature들이 있고 feature들이 어떻게 관계되었는지가 중요하다.예를 들자면 이 이미지에 선이 어디 있는지, 원이 어디 있는지는 필요없고, 선이 있는지, 원이 있는지, 선이 나올 때 원이 나오는 지 등이 중요하다.

이렇게 서로 다른 feature들 간의 연관성은 covariance를 활용해 측정한다.Covariance matrix는 여기서 Gram matrix라고 한다.어느 두 filter로 인한 feature가 동시에 자주 등장하면 Cov 값이 커질 것이고, 그렇지 않다면 작아질 것이다.

새로운 이미지를 생성하기 위해 style에 대한 loss function을 정의한 것이다.
Source image의 Gram matrix와 새롭게 만들어진 image의 Gram matrix의 차이를 loss로 만들고,
이를 줄이며 style transfer를 진행한다.

물론 Content에 대한 loss function도 필요하다.
Content는 spatial position에 초점을 맞추니, feature와 image를 그냥 match시켜 정의한다.
즉 모든 position, 모든 filter의 차이의 합이 곧 loss가 된다.Style의 loss와는 다르게 모든 layer에 대해 합치지 않고, 특정 layer에서 loss를 구한다.이 loss들의 합을 최소화하는 x를 구해, 새로운 이미지를 생성한다.

그렇게 생성된 이미지들의 몇 가지 예시이다.